
Cache Hierarchy and Levels
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to Cache Levels
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we're going to discuss the different levels of cache in modern processors. Can anyone tell me why caches are necessary?

Caches are used to speed up the access to frequently used data, right?
Exactly! Now, we have L1, L2, and L3 caches. Let’s start with L1. Can anyone describe its characteristics?

L1 is the smallest and fastest cache, located closest to the CPU.
Correct! It also has two parts: L1I for instructions and L1D for data. Now, what about L2?

L2 is larger than L1 but slower, and it's often shared between cores.
Right! And how does L3 differ from L2?

L3 is the largest among them and the slowest, shared among all cores.
Great job! Remember, this hierarchy helps in optimizing memory access by keeping frequently used data closer to the CPU. Now, let’s quickly summarize what we learned: L1 is fast and small, L2 is larger and slower, and L3 is the largest and slowest cached memory shared by all cores.
Cache Placement
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Now, let's dive into how these different caches work together. Can anyone explain the concept of locality of reference?
Locality of reference means that programs tend to access the same set of data locations repeatedly.
Exactly! Locality is crucial for cache efficiency. How do you think this influences cache design?
It probably allows caches to store recent or nearby data to improve access times.
Right on! By placing frequently accessed data in the faster L1 cache, for instance, and progressively moving less accessed data to L2 or L3, we can significantly enhance performance. Can someone summarize how cache placement optimizes memory access?
Caches store data closer to the CPU based on how often it's accessed, speeding up processing.
Excellent! The more we understand these principles, the better we can optimize system performance.
Cache Hierarchy in Practice
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let’s now consider a practical scenario: How does the cache hierarchy impact the performance of a CPU during multitasking?
If one program is using data that fits in L1, it'll run faster than data that needs to go all the way to L3.
That's correct! The cache hierarchy increases efficiency by ensuring that multiple programs can effectively share the while utilizing the closer cache levels. How does this relate to response time in user applications?
It means applications can respond quickly because most of the necessary data is readily accessible from the faster caches.
Exactly! This shows how efficient cache hierarchy scales up performance for multitasking environments. Now, let’s summarize today’s lesson by reiterating: Caches get progressively larger and slower. The hierarchical structure ensures optimal data retrieval, improving performance.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
Modern processors utilize a structured cache hierarchy consisting of multiple levels, namely L1, L2, L3, and potentially L4 caches. Each level has varying sizes and speeds, strategically improving memory access times by exploiting locality of reference.
Detailed
Cache Hierarchy and Levels
Modern processors employ a hierarchical architecture of caches designed to enhance overall system performance by reducing data access times. This hierarchy is organized into several cache levels:
- L1 Cache: This is the smallest and fastest cache, positioned closest to the CPU core. It is divided into two sections: L1I for instructions and L1D for data.
- L2 Cache: This cache level is larger than L1 but slower, often shared among multiple cores within multi-core processors.
- L3 Cache: The largest and slowest among the main cache levels, typically shared across all cores in contemporary processors.
- L4 Cache: Found in high-end systems, this cache level may exist off-chip or be integrated with the memory subsystem.
The arrangement of these cache levels optimizes memory access by placing the most frequently accessed data closest to the CPU (L1), while less frequently used data occupies the larger, slower L2 and L3 caches. This hierarchical strategy is crucial for improving the performance of CPU-intensive applications by minimizing the gaps in speed between the CPU and slower memory components.
Youtube Videos
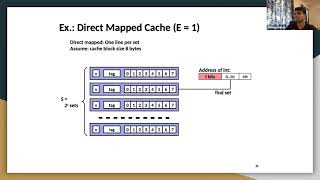
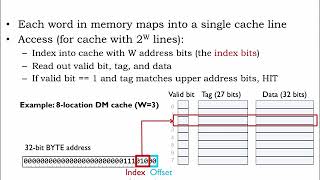
Audio Book
Dive deep into the subject with an immersive audiobook experience.
Introduction to Cache Levels
Chapter 1 of 6
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Modern processors use multiple levels of cache, each with its own size, speed, and access time. The cache hierarchy improves performance by exploiting locality of reference.
Detailed Explanation
In modern computing, processors are designed with several levels of cache to enhance performance. Each cache level comes with different specifications in size and speed. The primary goal of having various cache levels is to take advantage of 'locality of reference', which suggests that programs frequently access the same memory locations or data items. By structuring the cache this way, the system can retrieve data more swiftly, leading to improved overall performance.
Examples & Analogies
Think of a library where you need to access books frequently. Instead of looking for every book in the entire library, you have smaller shelves nearby with the most popular books. This is similar to how caches work: the smaller caches hold frequently accessed data, making it quicker to retrieve just like having easy access to your favorite books.
L1 Cache
Chapter 2 of 6
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
L1 Cache: The smallest and fastest cache, located closest to the CPU core. It is split into two parts: one for instructions (L1I) and another for data (L1D).
Detailed Explanation
The L1 cache is crucial for performance since it's the first place the CPU looks for data and instructions. Being the smallest and fastest, it minimizes latency, which means less waiting time for the CPU. The L1 is divided into two distinct sections: the L1 Instruction Cache (L1I) which stores instructions that the CPU needs to execute, and the L1 Data Cache (L1D) which holds data that the CPU will need to perform its operations right away.
Examples & Analogies
Imagine a chef in a kitchen. The L1 cache is like the countertop where the chef keeps the most frequently used ingredients ready for immediate cooking, while the rest of the pantry contains less frequently used items. This setup allows the chef to prepare meals much faster without searching through the entire pantry.
L2 Cache
Chapter 3 of 6
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
L2 Cache: Larger than L1, but slower. It is often shared among multiple cores in multi-core processors.
Detailed Explanation
The L2 cache serves as a bridge between the L1 cache and the slower main memory. While bigger than L1, it is not as fast, making it a secondary tier for cache storage. In many processors, especially those with multiple cores, the L2 cache can be shared among these cores, providing a larger storage space for data and instructions that are accessed more frequently than the rest.
Examples & Analogies
If the L1 cache is the chef's countertop, think of the L2 cache as the kitchen’s refrigerator. It holds additional ingredients that are not used as often but are still needed regularly. Sharing the refrigerator between several chefs (or CPU cores) ensures that everyone has easy access to the essential ingredients without scrambling to the pantry.
L3 Cache
Chapter 4 of 6
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
L3 Cache: The largest and slowest cache, usually shared across all cores in modern processors.
Detailed Explanation
The L3 cache is the largest among the cache levels. Its speed is comparatively slower than that of L1 and L2 caches; however, it is critical for holding data that does not fit into the smaller, faster caches. This cache is typically shared across all CPUs in a multi-core processor system, allowing for a greater capacity to reduce latency when accessing less frequently used data.
Examples & Analogies
Continuing with our kitchen analogy, the L3 cache can be compared to the pantry itself. While it’s the slowest option when it comes to retrieving ingredients, it provides a larger selection of items that chefs (CPU cores) can access collaboratively. They might have to spend a little more time going to the pantry, but they can find things that the countertop or refrigerator might not hold.
L4 Cache
Chapter 5 of 6
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
L4 Cache: In some high-end systems, an additional level of cache exists, often found off-chip or integrated with the memory subsystem.
Detailed Explanation
The L4 cache is not as commonly used as the other levels but can exist in high-performance computing environments. It serves as an additional layer, providing even more space for data storage, usually located off the main chip. This allows for accessing a larger volume of data that might not fit within the existing cache levels.
Examples & Analogies
Think of the L4 cache as a storage room for a restaurant, which isn't part of the kitchen but still holds remarkable quantities of both seasonal items and bulk supplies. Whenever the chef needs something that isn't available on the countertop or in the refrigerator, this storage room can come in handy to meet specific demands.
Cache Placement
Chapter 6 of 6
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Cache Placement: The different cache levels work together to optimize memory access, where each level stores data closer to the CPU and progressively handles less frequently accessed data.
Detailed Explanation
Cache placement refers to how the hierarchy of cache levels works in concert to ensure efficient data access. The lower cache levels (like L1) hold the most frequently accessed data, while as the level increases (L2, L3), the frequency of access generally decreases. This structured hierarchy means that the CPU can access data at progressively quicker speeds based on the distance from the core to the cache.
Examples & Analogies
Consider how a teacher organizes a classroom. Important, frequently used supplies (like pencils and papers) are right on the desk (L1), while less commonly used items (like construction paper) might be in a nearby cupboard (L2), and bulk supplies (like reams of paper) are stored further away in the supply room (L3). The placement ensures that essential items are within easy reach while still having access to additional resources when needed.
Key Concepts
-
Cache Hierarchy: The arrangement of different cache levels (L1, L2, L3) to optimize performance.
-
Locality of Reference: The principle that frequently accessed data is kept closer to the CPU for quicker access.
-
L1 Cache: Fastest and first level of cache, divided into instruction and data portions.
-
L2 Cache: Intermediate size and speed, often shared among multiple CPU cores.
-
L3 Cache: Largest but slowest cache level, shared across all CPU cores.
Examples & Applications
In a gaming application, the first few actions taken will likely hit the L1 cache, allowing for quick retrieval of data, whereas less frequently accessed background data might need to access the slower L3 cache.
When running multiple applications, the data accessed by the spreadsheet software can remain in L1 cache as the user frequently interacts with it, whereas data accessed by other applications may reside in L3.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
When you need quick access, don’t delay; Remember L1 is where data will stay.
Stories
Imagine a library (the CPU) that hires several assistants (cache levels). The nearest assistant (L1) fetches books (data) swiftly for you, while the further down assistants (L2 and L3) manage larger references but take longer.
Memory Tools
L1, L2, L3 - small, medium, large; speed, space, charge.
Acronyms
In 'CACHE', C stands for 'Consistency', A for 'Access speed', H for 'Hierarchy', and E for 'Efficiency'.
Flash Cards
Glossary
- Cache
A high-speed storage used to temporarily hold frequently accessed data and instructions to enhance system performance.
- L1 Cache
The smallest and fastest level of cache located closest to the CPU core, divided into instruction and data caches.
- L2 Cache
A larger but slower cache compared to L1, often shared among multiple CPU cores.
- L3 Cache
The largest and slowest cache level in modern processors, generally shared across all CPU cores.
- L4 Cache
An optional cache level found in high-end systems that may reside off-chip or combine with memory subsystems.
- Locality of Reference
The tendency for programs to access the same set of data locations frequently.
Reference links
Supplementary resources to enhance your learning experience.