
Caches
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to Caches
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we're discussing caches, which are crucial for improving the performance of our computers. To start, can anyone tell me what cache memory is?

Isn't it a type of fast memory that sits between the CPU and main memory?
Exactly! Cache memory stores frequently accessed data to reduce access times. Remember: Cache is like a quick-access toolbox for the CPU. Can you think of why that would be important?

It makes everything run faster, right? Because it cuts down on the time spent fetching data from the slower main memory.
Right on! The CPU doesn’t have to wait as long for data. Now, what do you think is the purpose of caching?

To reduce the gap between CPU speed and memory access time?
Correct! Caches improve performance by minimizing that gap.
Cache Hierarchy and Levels
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Let's move on to cache hierarchy. Can anyone name the different levels of cache?

L1, L2, and L3 - plus sometimes L4!
Excellent! L1 is the smallest and fastest, found closest to the CPU. What about L2 and L3?
L2 is larger than L1 but slower and can be shared among cores. L3 is the largest and slowest.
Correct! Each level has a role: L1 for speed, L2 for capacity, and L3 for sharing across cores. Now, can anyone explain why we have these multiple levels?
To store data closer to the CPU and manage the trade-off between speed and capacity?
Exactly! It’s all about optimizing memory access.
Cache Access Principles
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Next, let’s discuss cache access principles. Who can define spatial and temporal locality?
Spatial locality is when you access data nearby and temporal locality is when you access the same data repeatedly over time.
Wonderful summary! Caches leverage these principles. How do they actually store data based on these principles?
By loading blocks of contiguous data for spatial locality and keeping recently accessed data for temporal locality!
Exactly! Now, what about cache mapping techniques?
We have direct-mapped, associative, and set-associative caches.
Right! Can anyone briefly explain how they differ?
Direct-mapped maps data to exactly one line, associative allows any address in any line, and set-associative is a mix of both.
Great work, everyone! Understanding these principles helps us decode how efficient caches can be.
Cache Misses and Handling
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let's move on to cache misses. Can someone tell me what a cache miss is?
It’s when the requested data isn’t found in the cache.
Correct! What are the types of cache misses we can identify?
Compulsory misses, capacity misses, and conflict misses!
Exactly! Now, how do we handle these misses?
We have to fetch the data from slower memory, like main memory, which can be quite slow.
Great point. To manage performance, what are some common replacement strategies we can use?
Least Recently Used and First-In, First-Out are common strategies!
Correct! Understanding these strategies will help us minimize the negative impacts of cache misses.
Write Policies in Caches
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Lastly, let’s talk about write policies. What are the two primary write policies?
Write-Through and Write-Back!
Correct! Can someone elaborate on how Write-Through works?
In Write-Through, any data written to the cache is also immediately written to main memory.
Exactly! While it ensures data consistency, what’s a drawback?
It can slow things down because it increases write operations to memory.
Well done! Now, what can you tell me about Write-Back?
With Write-Back, changes are only written to cache, and main memory is updated when the cache line is evicted.
Excellent! This method reduces memory write traffic but can add complexity. Great job today, everyone!
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
Cache memory acts as an intermediary between the CPU and main memory, storing frequently accessed data to minimize access times. Multiple levels of cache (L1, L2, L3, and optional L4) leverage principles like locality of reference and various mapping techniques to optimize data retrieval and ensure efficient performance.
Detailed
Caches
Cache memory is crucial in computing architecture, serving as a high-speed storage area that enhances system performance by temporarily holding frequently accessed data. By significantly reducing the average access time to data, caches help bridge the performance gap between the CPU and slower main memory.
Cache Hierarchy
Modern processors employ multiple levels of cache, each with distinct characteristics. The L1 Cache is the fastest and smallest, directly connected to the CPU. The L2 Cache is larger and slower and may be shared among processor cores. The L3 Cache is even larger and works across multiple cores, while the optional L4 Cache may exist off-chip. These caches are strategically designed to exploit spatial and temporal locality, allowing efficient memory access.
Access Principles
Cache access is influenced by principles like locality of reference—where data locations accessed close to one another are prioritized (spatial locality) and recently accessed data is immediately retrievable (temporal locality). Mapping techniques, such as Direct-Mapped, Associative, and Set-Associative caches, dictate how data is stored and accessed, while replacement strategies help manage cache memory when full.
Cache Misses and Write Policies
Cache misses occur when requested data isn't found in cache, leading to penalties that can detrimentally affect performance. Write policies, such as Write-Through and Write-Back, determine how modifications to data in the cache are handled. Lastly, cache coherence is critical in multi-core systems to maintain consistency across various caches.
Youtube Videos
Audio Book
Dive deep into the subject with an immersive audiobook experience.
Introduction to Caches
Chapter 1 of 5
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Cache memory is a small, fast storage located between the CPU and main memory. Its role is to store frequently accessed data to reduce the time needed to access that data from slower memory.
● Definition of Cache: Cache is a high-speed storage used to temporarily hold frequently accessed data and instructions, improving overall system performance.
● Purpose of Caching: To reduce the average time it takes for the CPU to access data from main memory and decrease the gap between the speed of the CPU and the memory access time.
Detailed Explanation
Cache memory acts like a quick-access drawer for the processor. Instead of searching through a slow storage area for data, the CPU checks the cache first.
The purpose of caching is to minimize the time the CPU spends waiting for data. By storing often-used data in the fast cache memory, the system performs better overall. Think of it as having your most-used books on your desk, rather than on a shelf across the room.
Examples & Analogies
Imagine you're cooking and need spices frequently. Instead of searching through your pantry (slow storage), you keep a small selection of the most-used spices on the kitchen counter (cache). This setup saves you time when cooking, just like how a cache saves the CPU time when accessing data.
Cache Hierarchy and Levels
Chapter 2 of 5
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Modern processors use multiple levels of cache, each with its own size, speed, and access time. The cache hierarchy improves performance by exploiting locality of reference.
● Levels of Cache:
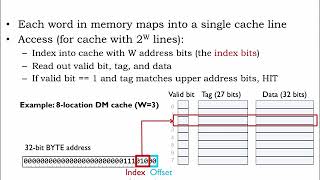
○ L1 Cache: The smallest and fastest cache, located closest to the CPU core. It is split into two parts: one for instructions (L1I) and another for data (L1D).
○ L2 Cache: Larger than L1, but slower. It is often shared among multiple cores in multi-core processors.
○ L3 Cache: The largest and slowest cache, usually shared across all cores in modern processors.
○ L4 Cache: In some high-end systems, an additional level of cache exists, often found off-chip or integrated with the memory subsystem.
● Cache Placement: The different cache levels work together to optimize memory access, where each level stores data closer to the CPU and progressively handles less frequently accessed data.
Detailed Explanation
Caches are structured in levels to enhance performance.
- L1 Cache is the fastest and closest to the CPU for immediate data access. It’s divided into two areas — one for instructions and one for data, allowing quick retrieval of what the CPU needs right away.
- L2 Cache is larger and slightly slower but can serve multiple CPU cores, acting as a secondary quick-access storage area.
- L3 Cache is the biggest and slowest, shared by all cores, providing a pool of data that is accessed less frequently.
- L4 Cache optional, is used in high-performance systems to further aid data access speed.
This layered approach allows the CPU to quickly access data it uses most often, reducing delays and speeding up overall performance.
Examples & Analogies
Think of a library as a cache system. The L1 Cache could be the reference desk with the most requested books for immediate access. The L2 Cache would be like a nearby reading room holding frequently borrowed books. The L3 Cache would be the general collection in the stacks that patrons look for less often. Finally, the L4 Cache might represent a storage facility for rare books that are not needed frequently, but are available when required.
Cache Access Principles
Chapter 3 of 5
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Cache access is governed by several principles, including locality of reference and cache mapping strategies, which determine how data is stored and retrieved.
● Locality of Reference:
○ Spatial Locality: Refers to accessing data locations that are close to each other. Caches exploit this by loading contiguous blocks of data.
○ Temporal Locality: Refers to the tendency to access the same memory locations repeatedly in a short time. Caches take advantage of this by keeping recently accessed data in cache.
● Cache Mapping Techniques:
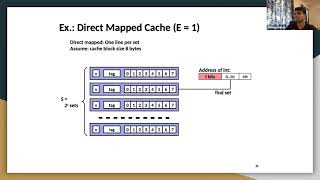
○ Direct-Mapped Cache: Each memory address maps to exactly one cache line. This is the simplest cache mapping technique but can lead to cache conflicts.
○ Associative Cache: A cache line can store data from any address. This reduces cache conflicts but is more complex.
○ Set-Associative Cache: A compromise between direct-mapped and fully associative caches. The cache is divided into sets, and each memory address can map to any cache line within a set.
Detailed Explanation
Cache design relies on two main principles:
- Locality of Reference: This means if a program accesses one data item, it’s likely to access nearby data (Spatial Locality) or the same item again soon (Temporal Locality). Caches take advantage of this by storing groups of nearby data together or keeping frequently used data readily available.
- Cache Mapping Techniques: This refers to how data is organized in the cache.
- Direct-Mapped Cache places each piece of data in a specific spot, which is straightforward but can cause conflicts if two pieces of data map to the same spot.
- Associative Cache allows data to be stored in any available space, reducing conflicts but increasing complexity.
- Set-Associative Cache mixes both methods, organizing data into sets where any data can fit into any slot in a set, optimizing access while managing conflicts effectively.
Examples & Analogies
Think of a file cabinet as cache storage. Spatial Locality is like putting related files (like student records or invoices) in sequence in the drawer, so when you access one file, you often find what you need next to it. Temporal Locality is that you might pull out the same documents multiple times in a day, so keeping them easily accessible at the front of the drawer makes sense.
For cache mapping, Direct-Mapped is like having a slot for each file in a very organized cabinet, potentially leading to overcrowding in that one slot. Associative is more like having a free-for-all drawer where any file can go anywhere, but it’s harder to find them. Set-Associative is like having cabinets divided by category, allowing some organization while still offering flexibility.
Cache Misses
Chapter 4 of 5
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
A cache miss occurs when the requested data is not found in the cache, requiring the data to be fetched from a slower memory level.
● Types of Cache Misses:
○ Compulsory Misses: Occur the first time a data item is accessed.
○ Capacity Misses: Occur when the cache cannot hold all the data needed by the program.
○ Conflict Misses: Occur when multiple data items map to the same cache location, causing evictions.
● Handling Cache Misses:
○ Cache Miss Penalty: The time it takes to fetch data from a lower memory level, typically main memory or even secondary storage.
○ Cache Replacement Strategies: These strategies aim to minimize cache misses by ensuring that the most useful data stays in the cache.
Detailed Explanation
When the CPU needs data that isn’t in cache, it experiences a cache miss. There are three main types of misses:
- Compulsory Misses occur the very first time a data item is accessed; it’s unavoidable.
- Capacity Misses happen when the cache is too small to hold all the data for the current workload, meaning older data gets pushed out.
- Conflict Misses arise when two or more data items are forced to compete for the same cache location, leading to one of them being evicted.
When a cache miss happens, there’s a cost: Cache Miss Penalty, which is the time taken to retrieve the data from the slower storage (main memory). Efficient management of what stays in cache and what gets removed is crucial to minimizing the impact of cache misses.
Examples & Analogies
Consider a simple coffee shop that has a limited counter space (the cache). When someone orders coffee for the first time, that’s a compulsory miss since they’ve never served it before. If the shop receives too many unique orders beyond their limited counter space, some items will have to be removed to make room for new ones -- that’s a capacity miss. If two customers want the same exact blend at the same time, and the counter can only hold one, they’ll bump heads—leading to a conflict miss. The additional time spent making a fresh pot of coffee when their order isn’t ready illustrates cache miss penalty.
Write Policies in Caches
Chapter 5 of 5
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
When data is modified in memory, caches must decide how to handle those changes. This section covers the two primary write policies used in caches.
● Write-Through: Every write to the cache is immediately written to main memory. This ensures data consistency but can be slower due to the higher write traffic to main memory.
● Write-Back: Changes are only written to the cache, and main memory is updated later when the cache line is evicted. This reduces the number of write operations to main memory but requires extra complexity to manage the consistency of data.
Detailed Explanation
Caching also involves how data is written back to memory, which is determined by two main policies:
- Write-Through means every change in the cache immediately reflects in the main memory. This keeps everything consistent but can slow down processes because the system constantly updates the slower memory.
- Write-Back only updates the cache first. Main memory gets updated later when that data is removed from the cache. This is quicker but introduces complexity as it can lead to situations where the data in cache and memory differ temporarily until updated.
Examples & Analogies
Imagine you're a chef. Write-Through is like immediately updating your recipe book every time you modify an ingredient in your dish. It ensures the book is always correct, but it slows you down. Write-Back is like making adjustments to the dish first and only noting down the changes in the recipe book once you finish. You work faster, but if someone else looks at your book before you finish, they might see an outdated recipe. This reflects the potential inconsistency that comes with Write-Back.
Key Concepts
-
Cache: A high-speed temporary storage for frequently accessed data, improving access times.
-
Cache Hierarchy: The arrangement of multiple cache levels (L1, L2, L3) that balance size and speed.
-
Locality of Reference: The tendency to access data close in time and space, optimizing cache effectiveness.
-
Cache Miss: A failure to find the requested data in the cache, leading to longer retrieval times.
-
Write Policies: Rules governing how data is written to cache and main memory, impacting performance.
Examples & Applications
When a user opens a document on a computer, the data may be loaded into the L1 cache. If they frequently access it, it remains in the cache, reducing future access times.
In gaming, textures and models are often cached to quickly retrieve and render graphics without reloading from main memory, improving performance.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
Cache so fast, keep it near, data retrieval without fear.
Stories
Imagine a librarian (the CPU) who keeps an index (the cache) of frequently borrowed books (data) to quickly serve students (users). If a book isn't in the index, the librarian must search the entire library (main memory) to find it.
Memory Tools
Remember C-LR: Cache-Locality-Reference for understanding cache principles.
Acronyms
CACHE
Caching Aids CPU's High performance Efficiency.
Flash Cards
Glossary
- Cache
A high-speed storage area that temporarily holds frequently accessed data to decrease access time.
- Locality of Reference
A principle that describes how data access is often localized, meaning nearby data is frequently accessed together.
- L1 Cache
The fastest and smallest cache level, directly connected to the CPU core.
- L2 Cache
A larger, slower cache than L1, usually shared among processor cores.
- L3 Cache
The largest cache level, often shared across multiple cores.
- Cache Miss
A situation where the requested data is not found in the cache.
- WriteThrough
A write policy where data written to the cache is also written to main memory immediately.
- WriteBack
A write policy where data changes are only made in cache, and main memory is updated later.
Reference links
Supplementary resources to enhance your learning experience.