
Cache Optimizations
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Cache Prefetching
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we'll talk about one of the major techniques used to enhance cache performance: cache prefetching. Can anyone tell me what they think prefetching might involve?

Maybe it's about loading data into the cache before it's needed?
Exactly! Cache prefetching indeed involves preloading data based on predicted access patterns. It helps in reducing delays when this data is ultimately needed. We categorize prefetching into software-driven and hardware-driven. Anyone remember what those mean?

Software-driven means the programmer writes the code to predict the data access, right?
Correct! Software-driven prefetching relies on the programmer's foresight. Hardware-driven, on the other hand, is automatic, where the CPU itself anticipates what data will be needed next.

Can you give an example of when prefetching is useful?
Sure! It's particularly effective in repetitive processes or loops where data access patterns are predictable. To help remember, think of prefetching as placing your necessities closer to where you'll use them — it saves time!

Got it! It's like how I prepare my study materials ahead of time.
Exactly! This prepares us for improved efficiency! In summary, cache prefetching reduces wait times by anticipating data needs.
Multilevel Caches
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Let's dive into another important optimization: multilevel caches. Who can explain why we use multiple levels of cache?
Isn't it to balance speed and storage size?
Spot on! Multilevel caches allow us to balance the speed of access and the physical size of the cache. The cache hierarchy includes L1, L2, and L3, where L1 is the fastest, located closest to the CPU, while L3 is larger and shared between cores. Can anyone discuss how they might work together?
I think L1 caches the most frequently used data, while L2 and L3 contain less frequently used data.
Exactly! By storing data in this way, the CPU has rapid access to the most needed information, reducing the average access time. This technique exploits both spatial and temporal locality effectively.
Could you explain spatial and temporal locality again?
Certainly! *Spatial locality* means that if a particular data location is accessed, nearby data is likely to be accessed soon after. *Temporal locality* means data recently accessed will be accessed again shortly. This is why having multiple cache levels is efficient.
This makes so much sense! It’s like cooking dinner: you have your spices upfront and the less-used items further back.
Exactly! In summary, multilevel caches optimize access times by strategically placing data in proximity to the CPU based on access frequency.
Non-blocking Caches
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Finally, let's explore non-blocking caches. Who can explain what they think non-blocking means in this context?
Is it about not stopping the CPU even when it's waiting for data?
Exactly! Non-blocking caches allow the CPU to continue executing instructions while waiting for data from a cache miss. How do you think this impacts overall system performance?
It should improve throughput because the CPU doesn’t sit idly.
Correct! By preventing the CPU from stalling, we can maintain a higher level of processing. Think of it like a multi-tasker who doesn’t stop when waiting for a response but continues working on other tasks.
So, this helps in making sure that the overall speed hasn’t dropped due to waiting?
Precisely! In summary, non-blocking caches enhance throughput and efficiency by allowing the CPU to execute other operations during a cache miss.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
This section discusses techniques such as cache prefetching, multilevel caches, and non-blocking caches that improve cache performance. By utilizing these strategies, systems can exploit locality of reference and streamline CPU data access, ultimately improving overall efficiency.
Detailed
Cache Optimizations
Cache optimizations are crucial for enhancing the performance of computer systems, particularly in managing how data is accessed and stored in caches. This section covers several key techniques aimed at minimizing cache misses, which can significantly adversely impact performance.
Key Techniques:
- Cache Prefetching: This technique involves preloading data into the cache before it is actually needed, based on anticipated access patterns. Prefetching can either be implemented through software, where the programmer optimizes code, or hardware, where the processor automatically predicts needed data.
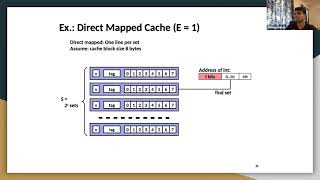
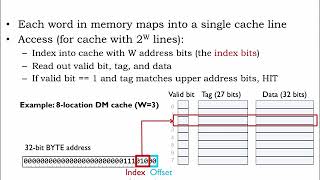
- Multilevel Caches: Employing a hierarchy of caches (L1, L2, and L3) allows for efficient data access by taking advantage of spatial and temporal locality. Each level of cache serves a distinct purpose, ensuring that the CPU has fast access to a wide range of data.
- Non-blocking Caches: These caches permit the CPU to continue executing instructions even while waiting for data to be fetched during a cache miss. This approach helps maintain high throughput and minimizes delays in processing.
Through these optimizations, systems can effectively reduce average memory access times, improving the overall performance of applications.
Youtube Videos
Audio Book
Dive deep into the subject with an immersive audiobook experience.
Cache Prefetching
Chapter 1 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Cache Prefetching: Involves preloading data into the cache before it is actually needed, based on predicted access patterns. Prefetching can be either software-driven or hardware-driven.
Detailed Explanation
Cache prefetching aims to improve the efficiency of the cache by anticipating which data will be required in the near future and loading that data into the cache proactively. This minimizes wait times when the CPU actually requests that data. Prefetching can be achieved through software instructions written by programmers or automatically handled by the hardware through algorithms that analyze access patterns.
Examples & Analogies
Imagine you're at a restaurant, and the server remembers your regular order. They start preparing your favorite dish as soon as you walk in, so by the time you take a seat and look at the menu, your food is ready. Similarly, cache prefetching prepares the data ahead of time, ensuring that it’s available when the CPU needs it.
Multilevel Caches
Chapter 2 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Multilevel Caches: Combining multiple levels of cache (L1, L2, L3) to exploit both temporal and spatial locality, providing faster access to data.
Detailed Explanation
Multilevel caches are designed to optimize access speeds by leveraging different cache levels with varying sizes and speeds. The L1 cache is the fastest but smallest, while L3 is larger but slower. By structuring caches in levels, the system can quickly access frequently used data (temporal locality) and data that’s located close together (spatial locality), resulting in overall improved performance.
Examples & Analogies
Think of a library with different rooms. The reference room (L1 cache) has only the most popular books that everyone frequently checks out, while the large storage room (L3 cache) has many books but is less easily accessible. When you need a book, you first check the reference room. If it's not there, you can find it in the storage room more reliably without having to cross the entire library every time.
Non-blocking Caches
Chapter 3 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Non-blocking Caches: Allow the CPU to continue executing while waiting for cache misses to be resolved, improving overall throughput.
Detailed Explanation
Non-blocking caches enhance performance by allowing the CPU to perform other tasks while waiting for data retrieval from slower memory levels. This means that instead of having to stop processing when a cache miss occurs, the CPU can work on other operations, thus improving overall system efficiency and reducing idle time.
Examples & Analogies
Imagine a waiter at a busy restaurant who takes multiple orders before returning to the kitchen. While waiting for an order to be prepared (the data to be retrieved), they can continue to help other customers. This multitasking approach allows the restaurant to serve more customers efficiently, just like how non-blocking caches allow the CPU to manage multiple tasks while data is being fetched.
Key Concepts
-
Cache Prefetching: Preloading data into the cache before it's accessed.
-
Multilevel Caches: Using multiple layers of caches to optimize data access.
-
Non-blocking Caches: Allowing the CPU continuing execution even during cache misses.
Examples & Applications
Considering a program that processes a large dataset iteratively—by prefetching, we can load the next chunk of data before the current chunk is finished processing.
In a multi-core system, if one core is waiting for data, non-blocking caches allow other cores to keep processing tasks.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
Cache prefetching, a key to speed, loads up data, we all need!
Stories
Imagine a chef who lays out all ingredients before cooking. That's like prefetching—preparedness leads to a smoother cooking experience!
Memory Tools
To remember cache levels: L1 is closest, 'L' means 'Lightning-fast'; L2 is 'Light' and bigger; L3 'Leads' but is slower.
Acronyms
Remember 'P.M.N.' for cache techniques
Prefetching
Multi-level
Non-blocking.
Flash Cards
Glossary
- Cache Prefetching
The technique of loading data into the cache before it is needed, based on anticipated access patterns.
- Multilevel Caches
A system architecture utilizing multiple layers of cache (L1, L2, L3) to optimize data access speed and efficiency.
- Nonblocking Caches
Caches that allow the CPU to execute other instructions while waiting for data to be loaded from a lower memory level.
Reference links
Supplementary resources to enhance your learning experience.