
Pipelining
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to Pipelining
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we’re diving into pipelining! This technique divides the execution of instructions into stages allowing parts of multiple instructions to be executed simultaneously. Can anyone share why this might be important?

It probably helps the processor run more instructions faster, right?
Exactly! This overlapping execution boosts the processor's overall performance. Let's remember 'Pipelining = Parallel Processing!'

What are the stages involved in pipelining?
Great question! There are five main stages: Instruction Fetch, Instruction Decode, Execute, Memory Access, and Write Back. Each is essential for the instruction lifecycle.

So, they all work together to speed things up?
Correct! This parallel execution forms the basis of why pipelining is so effective. In short, pipelining increases throughput by overlapping execution.
Pipeline Stages
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Now, let’s look closely at the stages: Could someone remind us what the first stage is?

That’s Instruction Fetch, right?
Absolutely! In the Instruction Fetch stage, the processor retrieves the instruction from memory. Next comes Instruction Decode. What happens there?
The instruction is decoded to find out what operation it needs to perform.
Exactly! The Execute stage then performs that operation, followed by Memory Access if needed. Finally, we have Write Back to the register file. Remembering this, we can use 'F-D-E-M-W' as a mnemonic to recall the stages!
What if one instruction hasn’t finished an earlier stage? Does that slow everything down?
Good point! That’s where hazards come in, which we’ll discuss in more detail shortly.
Pipeline Hazards
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let’s shift gears to pipeline hazards. Who can tell me what a data hazard is?
It’s when one instruction depends on data from a previous instruction, right?
Exactly! Such dependencies can create Read-after-Write hazards. Can anyone name another type of hazard?
Write-after-Read hazards can also occur when the writes happen out of order.
Spot on! And there’s also Write-after-Write hazards. Each type presents challenges that we must manage to maintain the pipeline's efficiency.
What about control hazards? I remember you mentioning branches.
Yes! Control hazards happen when the flow of instruction is altered, leading to potential delays. Branch prediction can help mitigate this issue. Remember: ‘Predict to Perfect!'
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
The pipelining process divides instruction execution into several stages, allowing different parts of multiple instructions to be processed concurrently. This section discusses the basic concepts of pipelining, its types, modern implementations, hazards, performance metrics, and challenges.
Detailed
Pipelining
Pipelining is a key technique utilized in modern processor design to improve performance through an increase in instruction throughput. It involves breaking down the execution of instructions into multiple stages that can be performed in parallel. The main stages include Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Write Back (WB). Each stage allows different parts of multiple instructions to be processed concurrently, significantly improving efficiency.
Various types of pipelining include Instruction Pipelining, Arithmetic Pipelining, and Data Pipelining, tailored for specific tasks. Modern processors have adopted advanced pipelining techniques, such as Superscalar Architecture, where multiple pipelines function simultaneously, and Out-of-Order Execution, allowing better resource utilization.
However, while pipelining enhances performance, it introduces challenges known as pipeline hazards, including data, control, and structural hazards. Solutions like pipeline stalls, forwarding, and branch prediction mitigate these issues. Performance is measured through metrics like throughput, latency, and speedup, highlighting the impact of pipelining on processor performance. As design continues to evolve, power efficiency, hardware limitations, and future trends challenge the realm of pipelining.
Youtube Videos

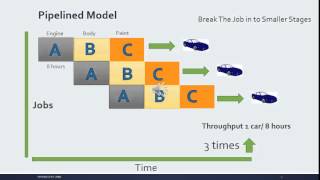
Audio Book
Dive deep into the subject with an immersive audiobook experience.
Introduction to Pipelining
Chapter 1 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
This section introduces the concept of pipelining, a technique used in modern processors to increase instruction throughput by overlapping the execution of multiple instructions.
● Definition of Pipelining: The process of dividing the execution of instructions into multiple stages that can be performed in parallel.
● Need for Pipelining: The motivation behind pipelining, which is to improve the performance of a processor by increasing instruction throughput.
● Basic Concept: Each stage of the pipeline processes a different part of an instruction, and multiple instructions can be processed simultaneously in different pipeline stages.
Detailed Explanation
Pipelining is a technique used in modern computer processors to improve the speed at which instructions can be executed. The basic idea is to break down the execution of instructions into multiple stages, much like an assembly line in a factory. Each stage completes a part of the instruction and moves it to the next stage. This overlap enables multiple instructions to be processed at the same time, significantly increasing the number of instructions completed in a given time frame.
Examples & Analogies
Consider a factory assembly line where different workers perform different tasks on a product at the same time. For example, one worker assembles the base, another installs components, and another tests the finished product. While one product is being tested, newer products can be at various other stages of assembly. This stands in contrast to a single worker completing one entire product before moving to the next, making the assembly line much more efficient.
Pipeline Stages
Chapter 2 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Pipelining breaks the execution of instructions into several stages. Each stage performs a different part of the instruction’s execution.
● Instruction Fetch (IF): The instruction is fetched from memory.
● Instruction Decode (ID): The fetched instruction is decoded to determine what operation it requires.
● Execute (EX): The operation specified by the instruction is performed.
● Memory Access (MEM): Data is read from or written to memory if required by the instruction.
● Write Back (WB): The result of the instruction is written back to the register file.
Each of these stages works concurrently in a pipeline, allowing multiple instructions to be in different stages at the same time.
Detailed Explanation
Pipelining divides the instruction execution process into five distinct stages: Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Write Back (WB). Each of these stages is responsible for a specific task. In the IF stage, the processor retrieves an instruction from memory. During the ID stage, the instruction is interpreted to determine what needs to be done. The EX stage performs the actual computation or operation dictated by the instruction. If the instruction requires data from memory, the MEM stage handles the reading or writing of that data. Finally, in the WB stage, the results of the instruction are written back to the processor's registers for future use. By having multiple instructions in different stages, the overall processing time is reduced.
Examples & Analogies
Think of ordering a meal at a fast-food restaurant. When you place an order (IF), the cashier rings it up (ID). Meanwhile, another employee is busy cooking the hamburger (EX). At the same time, a third person is preparing fries (MEM), and once everything is ready, the food is handed over to you (WB). All these tasks are happening in parallel, allowing the restaurant to serve more customers quickly.
Impact on Performance
Chapter 3 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Modern processors use advanced pipelining techniques to maximize efficiency and throughput.
● Superscalar Architecture: Multiple pipelines are used simultaneously, allowing the execution of more than one instruction at each clock cycle.
● Dynamic Scheduling: Instructions are dynamically scheduled to be processed in different stages of the pipeline to maximize resource usage.
● Out-of-Order Execution: Allows instructions to be executed out of order to fill idle stages in the pipeline, improving overall efficiency.
● Branch Prediction: Predicting the outcome of branches to prevent delays in the pipeline caused by control hazards.
Detailed Explanation
Modern processors not only implement traditional pipelining but also use advanced strategies to further enhance performance. In a superscalar architecture, multiple pipelines operate at the same time, meaning multiple instructions can be executed concurrently within a single clock cycle. Dynamic scheduling helps ensure that instructions are assigned to pipeline stages in an optimal way based on resource availability. Out-of-order execution allows the processor to rearrange the order of instructions so that it can better utilize the pipeline, filling any gaps that may exist. Branch prediction is a technique to guess the path of branch instructions (like ifs) to avoid delays caused by having to wait to fetch the next instruction after a branch.
Examples & Analogies
Imagine a traffic control system at a busy intersection. If traffic lights can predict when cars will arrive and manage multiple lanes with dedicated signals (superscalar), traffic can flow more smoothly without stopping frequently. Just like optimizing traffic flow, processors aim to maximize instruction execution while managing interruptions efficiently.
Key Concepts
-
Pipelining: A technique that allows overlapping execution of instructions to enhance throughput.
-
Pipeline Stages: The five key stages are Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Write Back (WB).
-
Pipeline Hazards: Challenges like data hazards and control hazards that must be managed to maintain performance.
-
Forwarding: A method to resolve data hazards by directly passing data between stages.
Examples & Applications
An example of pipelining can be seen in a 5-stage pipeline where one instruction is being fetched, another is being decoded, another is executing, and yet another is accessing memory simultaneously.
Consider a complex operation like multiplying two numbers, which is managed through arithmetic pipelining by breaking it into simpler parts that are processed in stages.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
In a pipeline flow, many tasks go; fetch, decode, execute, memory will show, and write back the result, with speed they will grow!
Stories
Imagine a factory assembly line where each worker specializes in one step of making a toy. As soon as one worker finishes their part, they pass it to the next, while simultaneously starting on a new toy, making the whole process faster - just like pipelining in a processor!
Memory Tools
To remember the stages of the pipeline: 'F-D-E-M-W' - Fetch, Decode, Execute, Memory Access, Write Back.
Acronyms
For Pipeline Hazards
‘D-C-S’ for Data
Control
and Structural hazards.
Flash Cards
Glossary
- Pipelining
The process of dividing instruction execution into multiple stages to allow for parallel processing.
- Instruction Fetch (IF)
The stage in which the instruction is retrieved from memory.
- Instruction Decode (ID)
The stage where the fetched instruction is interpreted to determine the necessary operation.
- Execute (EX)
The stage in which the actual operation specified by the instruction is performed.
- Memory Access (MEM)
The stage for reading from or writing data to memory if needed by the instruction.
- Write Back (WB)
The stage where the results of the executed instruction are written back to registers.
- Pipeline Hazards
Challenges that arise in pipelining, affecting the efficiency of instruction execution.
- Data Hazards
Conditions that occur when instructions depend on the same data.
- Control Hazards
Issues that arise from branching instructions, potentially disrupting the sequential flow.
- Forwarding
A technique for resolving data hazards by allowing data to be passed directly to later stages.
Reference links
Supplementary resources to enhance your learning experience.