
Pipelining in Modern Processors
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Superscalar Architecture
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today we’ll dive into superscalar architecture. Can anyone tell me what makes it different from basic pipelining?

I think it’s about having more than one pipeline, right?
Exactly! Superscalar architecture allows multiple instructions to be executed in parallel during a single clock cycle, which greatly enhances throughput.

How does that impact performance?
Great question! It allows the CPU to better utilize its resources and manage several instructions at once, significantly speeding up processing times.

Can you give an example of where this would be necessary?
Sure! Think of modern gaming or video processing—these tasks require a lot of computations and having multiple pipelines can drastically reduce the time needed to process graphics.
To summarize, superscalar architecture uses multiple pipelines for parallel instruction execution, enhancing performance in demanding scenarios.
Dynamic Scheduling
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Let’s explore dynamic scheduling. Who can explain what it involves?
I think it’s about rearranging instructions based on resources, right?
Correct! Dynamic scheduling allows the processor to adjust the order of instruction execution depending on resource availability, effectively filling any gaps in the pipeline.

What happens if an instruction requires data that’s not ready?
Excellent question! In such cases, the processor may wait for the data to become available while executing other independent instructions to keep the pipeline busy.
So, it helps keep everything running smoothly?
Absolutely! By dynamically scheduling instructions, the CPU minimizes idle time and maximizes execution efficiency.
In summary, dynamic scheduling enhances instructional flow by optimizing resource usage and minimizing stalls.
Out-of-Order Execution
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Now, who can explain out-of-order execution?
It’s when instructions are executed in a different order than they appear, right?
Correct! This technique helps to exploit available execution resources.
How does it prevent stalls in the pipeline?
Out-of-order execution allows instructions that do not depend on the results of previous instructions to proceed, thus keeping other stages busy. For example, if an instruction waits for data, the one after it can still execute if it doesn't depend on that data.
What’s the downside?
The complexity of managing instruction dependencies increases, but the trade-off is often worth the performance gains.
In summary, out-of-order execution maximizes instruction throughput by reordering execution based on data dependencies.
Branch Prediction
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Next, let’s discuss branch prediction. Who can summarize why it's important?
It helps to minimize stalls caused by branches in code, right?
Exactly! Whenever a branch occurs, the pipeline needs to decide which path to take. Correct predictions keep the pipeline filled, whereas misses lead to delays.
What happens during a misprediction?
The pipeline must be flushed, discarding prefetched instructions, which causes a performance hit.
How do processors predict branches?
Processors typically use historical data and algorithms to predict the likely patterns of branches, significantly improving accuracy over time.
In summary, branch prediction is essential for optimizing pipeline flow by proactively managing potential control hazards.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
Modern processors employ sophisticated pipelining strategies, such as superscalar architecture and out-of-order execution, to maximize performance by allowing multiple instructions to be executed simultaneously and efficiently. Branch prediction is also highlighted as a crucial technique in managing control hazards in pipelining.
Detailed
Pipelining in Modern Processors
Modern processors utilize advanced pipelining techniques that significantly enhance instruction throughput and overall efficiency. Pipelining enables the overlapping of multiple instruction execution phases, allowing greater utilization of CPU resources. Here are the key components discussed in this section:
Superscalar Architecture
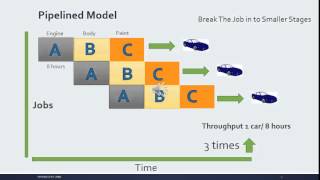
In a superscalar architecture, multiple pipelines operate concurrently, allowing more than one instruction to be issued and executed per clock cycle. This architecture improves parallel execution and overall throughput, distinguishing it from simpler pipelined designs.
Dynamic Scheduling
Dynamic scheduling plays a crucial role in processor efficiency. It allows the reordering of instruction execution based on the availability of execution units and data, ensuring that the pipeline remains filled optimally without unnecessary delays.
Out-of-Order Execution
Out-of-order execution is a technique where instructions are executed as resources become available rather than strictly following program order. This method helps in filling idle pipeline stages and improving instruction throughput.
Branch Prediction
Branch prediction is essential in reducing control hazards caused by conditional instructions. By forecasting the path of conditional instructions, processors can prefetch and execute instructions that follow the predicted path, thereby minimizing stall times in the pipeline.
These advanced techniques work in tandem to address the inherent challenges of pipelining, ensuring that modern processors remain efficient and capable of handling the increasingly complex workloads they face.
Youtube Videos

Audio Book
Dive deep into the subject with an immersive audiobook experience.
Superscalar Architecture
Chapter 1 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
● Superscalar Architecture: Multiple pipelines are used simultaneously, allowing the execution of more than one instruction at each clock cycle.
Detailed Explanation
Superscalar architecture is a design used in modern processors that allows more than one instruction to be executed at the same time. Unlike traditional single-pipeline processors, which can only work on one instruction per cycle, a superscalar processor can launch multiple instructions in parallel. This means that if a processor can execute two instructions at once, it effectively doubles its throughput, enhancing performance and efficiency.
Examples & Analogies
Think of a factory assembly line where multiple workers can operate on different parts of a product simultaneously. Instead of having one worker complete each task in sequence (like a single pipeline), each worker handles a different task at the same time, leading to faster overall production.
Dynamic Scheduling
Chapter 2 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
● Dynamic Scheduling: Instructions are dynamically scheduled to be processed in different stages of the pipeline to maximize resource usage.
Detailed Explanation
Dynamic scheduling allows processors to rearrange the execution order of instructions based on resource availability and data dependencies. This means that while one instruction is waiting for data, another independent instruction can be executed in its place. By doing this, processors can keep all pipeline stages busy, reducing idle time and improving efficiency.
Examples & Analogies
Imagine a restaurant where the chef has several dishes to prepare. If one dish is waiting for a special ingredient, the chef can quickly switch to prepare another dish that doesn’t require that ingredient. This flexibility allows the kitchen to operate continuously without causing delays.
Out-of-Order Execution
Chapter 3 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
● Out-of-Order Execution: Allows instructions to be executed out of order to fill idle stages in the pipeline, improving overall efficiency.
Detailed Explanation
Out-of-order execution is a method where instructions are executed as resources become available rather than strictly in the order they were issued. This technique helps alleviate stalls in the pipeline caused by waiting for data, as the processor efficiently utilizes its execution units by executing other instructions instead.
Examples & Analogies
Think of a relay race. If the runner holding a baton has to wait for the previous runner to pass the baton, the team falls behind. However, if the next runner can start sprinting while the previous runner is still running (but waiting to pass), the team maintains its speed, making the process much faster overall.
Branch Prediction
Chapter 4 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
● Branch Prediction: Predicting the outcome of branches to prevent delays in the pipeline caused by control hazards.
Detailed Explanation
Branch prediction is a technique used to guess which way a branch (like an 'if' statement) will go, allowing the processor to continue executing instructions without waiting for the actual result. If the prediction is correct, it saves time; if incorrect, the processor must discard those instructions and start over, which can cause delays.
Examples & Analogies
Imagine a driver approaching an intersection with a stop sign. If they guess that the road is clear and proceed, they save time. However, if they guess wrong and have to stop for a car they didn't see, the extra delay affects their travel time. Similarly, branch predictors aim to minimize such delays in processors.
Key Concepts
-
Superscalar Architecture: Allows simultaneous execution of multiple instructions.
-
Dynamic Scheduling: Rearranges instruction execution based on available resources.
-
Out-of-Order Execution: Executes instructions as resources become available, not strictly in order.
-
Branch Prediction: Predicts branch outcomes to minimize pipeline stalls.
Examples & Applications
In gaming, modern processors often utilize superscalar architecture to manage many simultaneous calculations required for rendering graphics.
Dynamic scheduling is used in processors to ensure that while one instruction waits for data, another independent instruction can proceed, maintaining pipeline efficiency.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
In a CPU race, many can place; with a pipeline that's fast, no time's a waste!
Stories
Imagine a chef managing several dishes at once, rearranging their cooking slots based on what's ready. That’s like dynamic scheduling in processors!
Memory Tools
S-D-O-B: Super Dynamic Out-of-order Branch prediction, for remembering key pipelining concepts!
Acronyms
P-R-O-B
Pipeline
Resources
Out-of-order
Branch (to recall main techniques in pipelining).
Flash Cards
Glossary
- Superscalar Architecture
A CPU design that allows multiple instructions to be issued and executed simultaneously in a single clock cycle.
- Dynamic Scheduling
A method in processors that rearranges the execution order of instructions based on resource availability.
- OutofOrder Execution
A technique in which the processor executes instructions as resources become available rather than strictly in order.
- Branch Prediction
The process of predicting the outcome of instructions that could result in a branch, to avoid pipeline stalls.
Reference links
Supplementary resources to enhance your learning experience.