
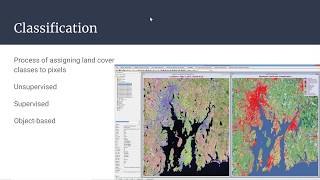
Image Classification Techniques
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Supervised Classification
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Let's talk about supervised classification. This method involves using training data where examples are already labeled. Can anyone name some algorithms used in this classification?

Is Maximum Likelihood one of those algorithms?
Exactly! Maximum Likelihood calculates the probability that a pixel belongs to a specific class. What about another one?

Support Vector Machine (SVM) is another, right?
Correct! SVM works by finding the best hyperplane for classification. Think of it as separating two different types of data points in a graph. Now, why do we need training data in supervised classification?

We need it to teach the algorithm how to categorize new data, right?
Yes! This 'training' enables the model to learn and make predictions. Great discussions! Supervised classification is crucial for accuracy in results.
Unsupervised Classification
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Now, let's shift to unsupervised classification. Who can explain how this differs from supervised classification?
Unsupervised classification doesn't use labeled training data. It groups similar data points based on their features.
Exactly! That means the algorithm identifies patterns without prior human input. Can anyone give me an example of an unsupervised method?
K-means is one of the methods.
Great job! K-means organizes data into k clusters to minimize variance within each cluster. How about ISODATA?
ISODATA allows for dynamic adjustment of the number of clusters based on the data.
Correct! This flexibility can improve the analysis significantly. Unsupervised classification is useful when we do not have labeled data, like in large-scale land cover assessments.
Object-Based Image Analysis (OBIA)
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let's discuss Object-Based Image Analysis, or OBIA. How is this technique different from traditional pixel-based methods?

OBIA segments images into objects rather than classifying individual pixels.
Exactly! This method captures spatial relationships and shapes, which is critical for high-resolution imagery. Can you think of a scenario where OBIA might be advantageous?
It would be useful in urban areas where buildings and roads need to be distinguished from one another.
Very good point! OBIA can immensely enhance the accuracy of classifications in complex landscapes. Remember, understanding the context and structure of the data is key.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
Image classification is essential in interpreting satellite images. This section details supervised classification, where user-defined data is utilized with algorithms like Maximum Likelihood, and unsupervised classification, which employs algorithms such as K-means. Additionally, Object-Based Image Analysis (OBIA) is introduced, emphasizing its effectiveness for high-resolution imagery.
Detailed
Image Classification Techniques
Image classification is a fundamental step in satellite image processing that converts raw satellite data into useful information by categorizing land cover types.
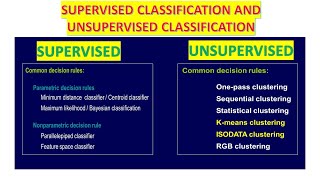
3.5.1 Supervised Classification
In supervised classification, analysts use training data, which consists of labeled examples, to teach the algorithm how to categorize the imagery. The most common algorithms include:
- Maximum Likelihood: Assumes the data follows a normal distribution and calculates probabilities of category membership.
- Support Vector Machines (SVM): A powerful classifier that finds the best hyperplane to separate categories in multidimensional space.
- Random Forest: An ensemble method that constructs a multitude of decision trees for improved accuracy and resilience against overfitting.
3.5.2 Unsupervised Classification
Unlike supervised methods, unsupervised classification does not require pre-labeled data. It identifies patterns and clusters in data using:
- K-means: Groups data into k clusters by minimizing variance within each cluster.
- ISODATA: An iterative approach that adjusts the number of clusters based on data distribution.
3.5.3 Object-Based Image Analysis (OBIA)
OBIA is particularly effective for high-resolution imagery, where segmentation of pixels into meaningful objects prior to classification can improve accuracy. This technique focuses on the context and structure of the data, using shape and pattern recognition to classify.
Overall, these image classification techniques are vital for applications across urban planning, environmental monitoring, and land cover assessment.
Youtube Videos






Audio Book
Dive deep into the subject with an immersive audiobook experience.
Supervised Classification
Chapter 1 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Involves user-defined training data.
Algorithms: Maximum Likelihood, Support Vector Machines (SVM), Random Forest.
Detailed Explanation
Supervised classification is a type of image classification where the user provides labeled training data to the algorithm. This means the user selects specific examples of different classes (like buildings, water, and vegetation) and trains the classification model to recognize these patterns in other imagery. The algorithms used in supervised classification include Maximum Likelihood, which estimates the probability of a pixel belonging to a certain class. Support Vector Machines (SVM) apply statistical learning theory to find the best boundary between classes, while Random Forest uses multiple decision trees to improve accuracy.
Examples & Analogies
Imagine teaching a child to recognize different types of fruits. You show them several examples of apples, bananas, and oranges. After seeing these examples, the child learns to identify these fruits in real life. This is similar to how supervised classification works.
Unsupervised Classification
Chapter 2 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Clustering-based technique using algorithms like K-means or ISODATA.
No prior training data required.
Detailed Explanation
Unsupervised classification does not rely on user-defined training data. Instead, it groups pixels into clusters based on their spectral properties, without any prior knowledge of the classes. The K-means algorithm is a popular method that partitions the image into K distinct classes by minimizing variance within each cluster. ISODATA extends K-means by allowing the number of clusters to adapt based on the data by merging or splitting clusters.
Examples & Analogies
Think of unsupervised classification like an art class where students work with different colors but without instruction on what to paint. They mix colors freely and create artwork based on their interpretations. Each piece can represent different themes or patterns, similar to how the algorithm identifies different land cover types.
Object-Based Image Analysis (OBIA)
Chapter 3 of 3
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Segments the image into meaningful objects before classification.
Useful for high-resolution imagery.
Detailed Explanation
Object-Based Image Analysis (OBIA) enhances classification by segmenting the image into meaningful objects, rather than treating each pixel individually. This process considers the spatial context, shape, and texture of groups of pixels to enhance classification accuracy, particularly for high-resolution images. Each segmented object is analyzed to classify it into different categories.
Examples & Analogies
Imagine assembling a puzzle. Instead of looking for individual pieces, you focus on assembling large sections based on color and shape. Once you have these sections, you can easily identify where they fit in the bigger picture. OBIA works similarly by grouping pixels, making it easier to classify complex images.
Key Concepts
-
Supervised Classification: A method that relies on user-defined training data to classify images.
-
Unsupervised Classification: A technique utilizing algorithms like K-means to classify images without prior training.
-
Object-Based Image Analysis (OBIA): A classification method focusing on object segmentation in high-resolution imagery.
Examples & Applications
An example of supervised classification is using a training dataset of labeled agricultural fields to differentiate between crops in a satellite image.
Unsupervised classification can be applied in wildlife studies, where researchers cluster various habitats from satellite imagery without pre-defined labels.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
For classes that we classify, training data must apply.
Stories
Imagine a teacher (Supervised) giving lessons to students (Data). The students are learning specific subjects, but one day, a group of students (Unsupervised) gathers without a teacher to explore what they can learn based on their similarities.
Memory Tools
Remember this: S for Supervised, T for Training; U for Unsupervised, N for No training needed.
Acronyms
BOOB
(B)oundaries
(O)bjects
(O)utcomes that OBIA focuses on in classification.
Flash Cards
Glossary
- Supervised Classification
A classification technique using training data with labeled examples to train algorithms for categorizing images.
- Unsupervised Classification
A technique that categorizes data without prior training data, based on inherent patterns or clustering.
- ObjectBased Image Analysis (OBIA)
A method that segments images into meaningful objects for classification, focusing on context and structure.
- Maximum Likelihood
An algorithm that classifies pixels based on statistical probabilities of data distributions.
- Support Vector Machines (SVM)
A classification algorithm that identifies the optimal hyperplane to separate different classes in a dataset.
- Kmeans
An unsupervised clustering algorithm that partitions data into k clusters to minimize variance.
Reference links
Supplementary resources to enhance your learning experience.