
Machine Learning on GPUs
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
GPU Utilization in Machine Learning
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we're exploring how GPUs are revolutionizing machine learning. Can someone tell me why parallel processing is advantageous for ML?

I think it allows multiple operations to be executed simultaneously, which speeds things up!
Exactly! GPUs can handle parallel tasks, like processing images in a convolutional neural network. This leads to rapid data processing. Can anyone provide an example?

I believe tasks like training models using large datasets benefit from using GPUs!
That's a great point! Tasks that require handling massive data volumes, such as training neural networks, are much faster with GPUs due to this parallelism.

Are there specific ML algorithms that benefit the most from GPU acceleration?
Yes, algorithms like deep learning, especially during tasks like matrix multiplication, leverage GPU capabilities significantly. Before finishing, let's remember the acronym 'GLAD' — GPUs for Learning and Acceleration in Deep learning.
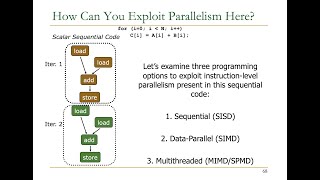
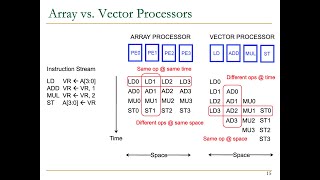
Advancements in SIMD and Vector Processing
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

As we discussed parallelism, what do you think advancements in SIMD technology mean for machine learning?

Could it mean more efficient data processing? Like being able to do more alongside each instruction?
Absolutely! With wider vector registers and advanced operations, SIMD improvements allow GPUs to handle data-intensive tasks better, enhancing speed and efficiency. Can someone summarize how SIMD works?
SIMD allows the same operation to occur on multiple data points simultaneously, right?
Correct! And in the context of ML, this means training models can happen more quickly than with older architectures.
Impact on Deep Learning Workflows
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
So, how have GPUs specifically impacted deep learning workflows?
I think they've made it quicker to train deep learning models.
Right! Every aspect, from the initial data preprocessing to the final inference phase benefits from GPU acceleration. Can anyone provide a specific operation that is affected?
Matrix multiplications are critical in neural networks, and they would definitely speed up with GPUs!
Great observation! Speeding up matrix multiplications translates to faster model training. Let's keep 'Multiply Faster with GPU' in mind for recalling this important concept.
Future Directions for GPU and Machine Learning
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Finally, let’s discuss future directions. What do you think the future holds for GPUs in machine learning?
There might be more integration with other technologies like quantum computing.
Exactly! As computational needs evolve, we may see hybrid approaches where GPUs work alongside quantum technologies. What does this integration imply for machine learning?
It would probably allow for solving problems that are currently too complex for classical computing.
Spot on! This means the future of ML could be even more promising with the right utilization of GPUs and emerging technologies. Remember the phrase 'Future Smart Computing' when thinking about these advancements.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
In this section, we delve into how GPUs have become essential in accelerating machine learning workflows, focusing on their ability to efficiently handle parallel computations. We also discuss the advancements in SIMD and vector processing that facilitate these enhancements, with an emphasis on deep learning training and inference.
Detailed
Machine Learning on GPUs
Machine Learning (ML) has experienced significant transformations with the advent of Graphics Processing Units (GPUs). This section highlights the pivotal role of GPUs in accelerating ML processes, particularly in deep learning, where extensive computations are necessary.
Key Points Covered:
- GPU Utilization in Machine Learning: GPUs are uniquely suited for handling parallel workloads typical in ML, allowing for faster data processing and model training. Their architecture supports performing the same operation across multiple data points, which is a natural fit for many ML algorithms.
- Advancements in SIMD and Vector Processing: The growth of machine learning has spurred innovations in SIMD (Single Instruction, Multiple Data) and vector processing capabilities, designed to improve computational efficiency in training and inference phases of deep learning.
- Impact on Deep Learning Workflows: Tasks such as matrix multiplication and convolutions involved in neural networks benefit enormously from GPU acceleration, leading to a drastic reduction in the time required for training models.
- Future Directions: As the demand for more complex ML algorithms increases, the interplay between GPUs and emerging technologies, possibly incorporating quantum computing, will likely shape future trends in machine learning capabilities.
Understanding these facets equips students with a comprehensive view of how GPUs not only enhance machine learning tasks but also position themselves as fundamental components of AI advancement.
Youtube Videos

Audio Book
Dive deep into the subject with an immersive audiobook experience.
Growing Use of GPUs for Machine Learning
Chapter 1 of 2
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
The growing use of GPUs for machine learning and AI workloads is expected to drive further innovations in SIMD and vector processing capabilities, particularly for accelerating deep learning training and inference.
Detailed Explanation
This chunk highlights the increasing reliance on Graphics Processing Units (GPUs) in the fields of machine learning and artificial intelligence. The use of GPUs is becoming more prevalent because they can handle the massive amounts of data and parallel computations required by these technologies. As more researchers and developers begin to use GPUs for machine learning, it is anticipated that this demand will lead to even more advancements in SIMD (Single Instruction, Multiple Data) and vector processing capabilities. These innovations will particularly focus on speeding up the training and inference processes of deep learning models, which are key aspects of machine learning.
Examples & Analogies
Imagine a chef preparing a meal for a large banquet. If the chef only uses one pot to cook one dish at a time, it will take much longer to get everything ready. However, if the chef has several pots (like GPUs with their multiple cores), they can cook multiple dishes simultaneously, significantly speeding up the process. In this analogy, the chef's ability to use multiple pots effectively is similar to how GPUs enhance the performance of machine learning tasks by handling many computations at once.
Innovations in SIMD and Vector Processing
Chapter 2 of 2
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
The innovations in SIMD and vector processing capabilities will particularly focus on accelerating deep learning training and inference.
Detailed Explanation
This chunk emphasizes that future improvements in SIMD and vector processing are directly tied to enhancing the efficiency and speed of deep learning algorithms. Deep learning often involves computations that are highly parallelizable, such as training neural networks with vast datasets. Innovations in SIMD allow for improved parallel processing by executing the same instruction on multiple data points at once, which leads to faster training times and quicker inference when applying the trained models. These advancements could include wider vector registers, more efficient processing algorithms, and optimized hardware architectures to further boost performance.
Examples & Analogies
Think of a relay race where each runner passes a baton to the next. If all the runners can sprint at their full speed (akin to SIMD efficiently handling multiple data points), the team will complete the race much faster than if they had to wait for one runner to cross the finish line before the next could start. In this way, the continuous improvements in SIMD technology will enable machine learning models to work more efficiently and accurately.
Key Concepts
-
GPU Acceleration: GPUs provide significant speedup in executing machine learning tasks that can be parallelized.
-
Parallel Processing: The ability of GPUs to process multiple tasks simultaneously enhances the efficiency and speed of machine learning workflows.
-
SIMD Architecture: The single instruction multiple data architecture allows GPUs to handle multiple data points with a single instruction.
-
Deep Learning Efficiency: GPUs drastically reduce the time for training deep learning models by efficiently executing necessary computations.
Examples & Applications
Training a convolutional neural network (CNN) on large image datasets is accelerated by utilizing GPUs, which perform the required matrix multiplications swiftly.
Using GPU-accelerated libraries such as TensorFlow or PyTorch can significantly cut down the training time for complex models like deep neural networks.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
With GPUs in play, learning speeds today, models train in a flash, no need for delay.
Stories
Imagine a race where each runner could execute their task simultaneously rather than waiting at the finish line. This is how GPUs allow deep learning models to train quickly!
Memory Tools
Remember 'GLOWS' for understanding GPUs: G for Graphics, L for Learning, O for Operations, W for Wide processing, and S for Speed.
Acronyms
Think 'PAPT' for GPU benefits - P for Parallelism, A for Acceleration, P for Performance, and T for Training.
Flash Cards
Glossary
- Machine Learning (ML)
A field of artificial intelligence that uses algorithms to allow computers to learn from and make predictions based on data.
- Graphics Processing Unit (GPU)
A specialized electronic circuit designed to accelerate the processing of images and graphics, now widely used for general-purpose computing.
- Single Instruction, Multiple Data (SIMD)
A parallel computing architecture where a single instruction operates on multiple pieces of data simultaneously.
- Deep Learning
A subfield of ML that uses neural networks with many layers to analyze various factors of data.
- Matrix Multiplication
An operation used in many algorithms that involves multiplying two matrices to produce a third matrix.
Reference links
Supplementary resources to enhance your learning experience.