
Vector, SIMD, GPUs
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to Vector Processing
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we’re going to explore vector processing. Can anyone tell me what vector processing is?

Is it when we use vectors in math?
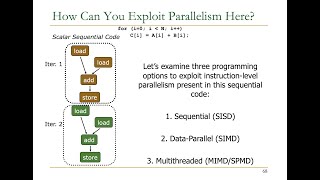
Good start! Vector processing is actually the technique of applying a single instruction to multiple data elements at the same time. This speeds up computations, especially in tasks that involve large datasets, like scientific computing and graphics.

So, it’s like doing multiple operations at once?
Exactly! This parallelism is achieved through vector registers, which hold multiple pieces of data. To remember this, think of 'Vector as a Vehicle'; it transports many pieces of information at once!

What do you mean by vector length?
Great question! Vector length refers to the number of data components in a vector register. The longer the vector, the more data can be processed in a single instruction cycle. Can anyone provide an example of where this might be useful?

Isn't it used in image processing where we have many pixels?
Exactly! Using vector processing can significantly improve the speed of tasks like rendering images.
To summarize, vector processing allows for efficient computation by processing multiple data elements simultaneously through the use of vector registers and varying vector lengths.
Understanding SIMD
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Moving on to SIMD, which stands for Single Instruction, Multiple Data. Who can tell me how SIMD works?
Does it mean one instruction for many data points?
Exactly! SIMD allows a single instruction to execute the same operation on multiple data points, which is a significant concept for enhancing parallelism in computing tasks, such as video encoding.
How is it different from SISD?
Great question! SISD stands for Single Instruction, Single Data, where one instruction operates only on one piece of data at a time. SIMD's ability to process multiple data points drastically improves performance for tasks that can leverage parallelism.
What’s an example of a SIMD architecture?
Modern architectures like Intel AVX and ARM NEON implement SIMD. They enable efficient processing in applications ranging from multimedia tasks to scientific simulations. Remember 'AVX=Advanced Vector Extensions'!
In summary, SIMD enhances performance by executing the same instruction across various data elements, significantly speeding up processes that can be performed concurrently.
GPU Architecture
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Now, let’s talk about GPUs. What do you think makes a GPU different from a CPU?
GPUs must be built for graphics?
That’s one aspect! While GPUs were originally designed for graphics rendering, they have evolved to handle large-scale parallel computations. They can execute many threads simultaneously, unlike CPUs that focus on single-thread performance.
How is this beneficial for machine learning?
Excellent question! In machine learning, tasks like matrix multiplications can be parallelized, and GPUs excel in these operations thanks to their massively parallel architecture.
What does GPGPU mean?
General-Purpose GPUs, or GPGPUs, refer to modern GPUs that can perform a wide range of computations outside of just graphics. For instance, NVIDIA's CUDA enables developers to utilize GPUs for various applications including AI and scientific simulations.
In summary, GPUs are specialized for parallel processing, making them ideal for tasks requiring significant computational power, particularly in fields like machine learning.
SIMD in GPUs
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Now, let’s discuss how SIMD capabilities are integrated into GPUs. Can anyone give me a brief description of SIMD in GPU contexts?
It means GPUs can perform the same operation on many pieces of data at once?
Precisely! Each GPU core acts as a SIMD unit that executes the same instruction over multiple data points in parallel, effectively improving performance for operations common in rendering and machine learning.
What about SIMT?
Great question! SIMT, or Single Instruction, Multiple Threads, is used in modern GPUs and allows more flexibility by permitting different threads to execute different instructions on their respective data elements.
So in deep learning, how does SIMD help?
In deep learning, SIMD allows operations such as matrix multiplication in neural networks to be executed on a large scale efficiently, leading to a decrease in training and inference time.
To summarize, SIMD is a core capability of GPUs that enhance their ability to conduct parallelized computations across multiple data points, especially beneficial in machine learning applications.
Vectorization and Compiler Optimization
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let's discuss vectorization. What does vectorization mean?
Is it turning single operations into multiple operations?
That's close! Vectorization is converting scalar operations, which work on single data points, into vector operations that can handle multiple data points simultaneously. This can drastically speed up performance.
Can compilers do this automatically?
Yes, modern compilers like GCC and Clang can automatically vectorize loops where applicable. However, sometimes manual optimization is necessary, particularly for performance-critical code.
What challenges do developers face during vectorization?
Excellent question! Loop dependencies can prevent vectorization if one iteration relies on the results of another. Additionally, memory alignment can impact performance, as SIMD instructions work best when data is aligned in memory.
To summarize, vectorization enhances performance by converting scalar into vector operations, but it does present challenges that developers must address.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
The section delves into vector processing techniques, the principle of SIMD for executing the same operation across multiple data elements, and the architecture of GPUs designed for parallel tasks. It covers practical applications in computing, graphics, and machine learning.
Detailed
Detailed Summary of Vector, SIMD, and GPUs
Introduction to Vector Processing
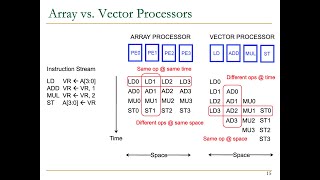
Vector processing is a computational technique that allows a single instruction to run across multiple data elements simultaneously, greatly enhancing performance for repetitive operations. It is particularly beneficial in fields such as scientific computing and machine learning. The key components of vector processing include vector registers, which store multiple data elements, and vector length, which indicates the number of elements that can be processed in one cycle.
SIMD (Single Instruction, Multiple Data)
SIMD expands on vector processing by executing the same instruction on several data points at once, thus leveraging data-level parallelism. Unlike SISD (Single Instruction, Single Data), SIMD can significantly improve efficiency for tasks like image and video processing. Current implementations, like Intel AVX and ARM NEON, provide modern processors with advanced SIMD capabilities.
SIMD Architectures and Instructions
SIMD architectures feature specialized vector units and instructions for efficient parallel processing. These include element-wise operations and gather/scatter operations that improve memory access and computational speed. SIMD's performance is notably higher than traditional methods, leading to faster processing times for large datasets.
Graphics Processing Units (GPUs)
GPUs are specialized processors optimized for handling massive parallel computations, making them ideal for tasks like graphics rendering and machine learning. Unlike CPUs, which are built for single-thread performance, GPUs can run thousands of threads concurrently. General-purpose GPUs (GPGPUs) further extend this capability beyond graphics, allowing for extensive applications in AI and scientific computations.
SIMD in GPUs
GPUs are inherently SIMD processors, executing identical instructions across multiple data points simultaneously. This efficiency is crucial in applications such as deep learning, where operations like matrix multiplication benefit from parallel processing.
Vectorization and Compiler Optimization
Vectorization transforms scalar operations into vector operations, enhancing performance through parallel processing. While modern compilers can automate this process, developers may also need to manually optimize code to overcome challenges like loop dependencies and memory alignment.
Future Trends in SIMD, Vector Processing, and GPUs
As computational needs grow, advancements in SIMD, vector processing, and GPUs are expected to continue, with next-generation SIMD extensions and increased use of GPUs in machine learning driving these innovations.
Youtube Videos

Audio Book
Dive deep into the subject with an immersive audiobook experience.
Introduction to Vector Processing
Chapter 1 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Vector processing is a technique that involves applying a single instruction to multiple data elements simultaneously, making it a powerful method for high-performance computing tasks that involve repetitive operations on large datasets.
Detailed Explanation
Vector processing is a method in computing where one instruction is used to perform operations on multiple pieces of data at the same time rather than one after another. This technique speeds up tasks that deal with large datasets, such as scientific calculations and graphics rendering. By processing data in parallel, it utilizes the available processing power of the system more efficiently.
Examples & Analogies
Think of vector processing like a chef who can chop multiple vegetables at once instead of one by one. Just as the chef saves time by using a sharp knife to quickly cut several vegetables, vector processing saves time in computing by applying one instruction to many data points.
Defining Vector Processing
Chapter 2 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Definition of Vector Processing: Involves performing the same operation on multiple pieces of data in a single instruction cycle. This is particularly useful in scientific computing, graphics, and machine learning tasks.
Detailed Explanation
Vector processing allows a single command to manipulate several data items at once. This is particularly useful for applications such as graphics rendering and simulations where identical operations need to be performed on many data elements. It enhances efficiency and decreases execution time, making it optimal for computational tasks that require repetitive calculations.
Examples & Analogies
Imagine a factory assembly line where a machine is set to glue labels onto multiple bottles at the same time instead of applying one label at a time. Just like this machine speeds up the production process, vector processing speeds up data processing.
Vector Registers
Chapter 3 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Vector Registers: Specialized registers in the processor that hold multiple data elements, allowing for parallel processing of those elements.
Detailed Explanation
Vector registers are specific types of storage within a computer's processor designed to hold multiple data values at the same time. By using vector registers, processors can perform operations on these values simultaneously, enhancing performance for tasks that can take advantage of this parallel processing capability.
Examples & Analogies
Consider a storage box that can hold several items at once, instead of small cubby holes that can only hold one item each. If you need to move ten books, having a single box that can carry them all at once is much more efficient than carrying each book one by one.
Vector Length
Chapter 4 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Vector Length: Refers to the number of data elements in a vector register. The length of the vector determines the degree of parallelism available in a vector processor.
Detailed Explanation
The vector length is an important factor in determining how many data elements can be processed in parallel within one operation. A longer vector length typically means that more data can be processed simultaneously, leading to greater performance enhancements for tasks that can be accelerated through parallel processing.
Examples & Analogies
Think of vector length like the number of lanes on a highway. A wider highway can accommodate more cars traveling side by side at the same time, similar to how a longer vector allows more data to be processed simultaneously.
Overview of SIMD
Chapter 5 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
SIMD (Single Instruction, Multiple Data) is a parallel computing method where a single instruction operates on multiple data points simultaneously. SIMD is a key concept in vector processing and is widely used in modern CPUs and GPUs.
Detailed Explanation
SIMD stands for Single Instruction, Multiple Data, and it allows a single command to carry out the same operation across many data points at once. This capability is crucial in enhancing performance in computing environments where tasks involve processing large amounts of similar data, such as image processing or simulations.
Examples & Analogies
Imagine a team of carpenters who need to cut the same size boards for a furniture set. Instead of each carpenter making individual cuts alone, they can work together, each cutting boards at the same time. This collaboration mimics how SIMD processes multiple data elements with one command, significantly speeding up the overall project.
Performance Benefits of SIMD
Chapter 6 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
SIMD allows a single instruction to perform the same operation on multiple data elements at once, exploiting data-level parallelism. It is commonly used for tasks such as image processing, video encoding, and scientific simulations.
Detailed Explanation
By enabling one instruction to affect multiple data points simultaneously, SIMD exploits data-level parallelism, boosting performance significantly in applicable scenarios. This capability is essential for high-speed tasks in areas like image rendering or real-time video processing, where efficiency is paramount.
Examples & Analogies
Think of SIMD like a team of cooks who are all making the same dish together. Instead of one person cooking every ingredient sequentially, every cook handles their part of the dish at the same time, speeding up meal preparation dramatically.
Comparison of SIMD and SISD
Chapter 7 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
SIMD vs. SISD: In SISD (Single Instruction, Single Data), a single instruction operates on a single piece of data. SIMD differs by processing multiple pieces of data with a single instruction, enabling significant performance improvements for parallelizable tasks.
Detailed Explanation
SISD (Single Instruction, Single Data) processes one piece of data at a time for each instruction, while SIMD uses one instruction to work on multiple data points simultaneously. This parallel capability allows SIMD to greatly outperform SISD in tasks where operations can be applied to numerous data elements at once.
Examples & Analogies
Imagine a student studying—if the student reads one page at a time, that’s like SISD. Conversely, if they read multiple pages of the same textbook all at once, that’s like SIMD, allowing for much quicker assimilation of information.
SIMD Execution Model
Chapter 8 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
SIMD executes the same instruction on multiple data elements simultaneously, increasing throughput for tasks that involve repetitive operations on large data sets.
Detailed Explanation
The execution model of SIMD allows the same instruction to be applied to multiple data points at the same time, increasing processing efficiency. This is especially useful in applications involving large datasets where the same kind of operation needs to be performed repeatedly, such as in scientific computing or image processing.
Examples & Analogies
Think about a printing press that prints multiple pages at once instead of single pages. Just like that machine can produce more pages in less time, SIMD enables faster data processing by applying one instruction to many data elements simultaneously.
SIMD in Modern Processors
Chapter 9 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Intel AVX: The Advanced Vector Extensions (AVX) provide SIMD capabilities for modern Intel processors, supporting wide vector registers (e.g., 256-bit, 512-bit).
Detailed Explanation
Advanced Vector Extensions (AVX) are instruction sets designed for modern processors that enhance their SIMD capabilities. These extensions allow processors to handle wider vectors, which means they can process more data simultaneously, thereby improving performance in applications that can leverage this technology.
Examples & Analogies
Think of AVX as an upgraded highway system that now has more lanes. This upgrade allows more cars to travel at the same time, significantly reducing traffic and speeding up travel times, just as enhanced vector registers allow processors to handle more data simultaneously.
ARM NEON SIMD
Chapter 10 of 10
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
ARM NEON: ARM processors use the NEON instruction set for SIMD, enabling efficient processing of multimedia and signal processing tasks.
Detailed Explanation
NEON is a SIMD architecture used in ARM processors designed specifically for high-efficiency processing of audio, video, and other multimedia tasks. By optimizing how data is processed concurrently, NEON facilitates faster and more efficient execution of operations relevant to media handling.
Examples & Analogies
Consider NEON like a specialized workshop that designs and assembles electronic gadgets faster than general-purpose assembly lines. This specialization allows ARM processors using NEON to handle multimedia processing tasks much more effectively.
Key Concepts
-
Vector Processing: Concurrent execution of a single instruction across multiple data elements.
-
SIMD: Single Instruction, Multiple Data; enhances performance through parallelism.
-
GPU Architecture: Designed for executing hundreds to thousands of threads concurrently.
-
General-Purpose GPUs: GPUs that perform tasks beyond graphics processing.
-
Vectorization: Converts scalar operations into vector operations to improve performance.
Examples & Applications
In image processing, vector processing can apply the same filter to many pixels at once.
Matrix multiplication in neural networks can utilize SIMD for faster training and inference.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
For SIMD, remember with glee, One instruction sets many free!
Stories
Imagine a race car (GPU) that zooms ahead of the slow single cars (CPU). Each driver must follow the same route (SIMD), making them efficient on the track!
Memory Tools
SISD vs. SIMD: Single, Single,; Multiple, Multiple — Use '1' and 'M' to remember!
Acronyms
SIMD
Single Instructions Make Data move fast!
Flash Cards
Glossary
- Vector Processing
Technique that applies a single instruction to multiple data elements simultaneously.
- Vector Registers
Specialized registers that hold multiple data elements for parallel processing.
- Vector Length
The number of data elements that a vector register can accommodate.
- SIMD
Single Instruction, Multiple Data; a method for executing the same operation on multiple data points at once.
- SISD
Single Instruction, Single Data; a method that operates on a single piece of data at a time.
- GPGPU
General-Purpose Graphics Processing Unit; GPUs configured to perform a wide array of computations beyond graphics.
- CUDA
Compute Unified Device Architecture; NVIDIA's platform for using GPUs for general-purpose computing.
- Vectorization
The process of converting scalar operations into vector operations.
Reference links
Supplementary resources to enhance your learning experience.