
SIMD in Deep Learning
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to SIMD in Deep Learning
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Welcome, everyone! Today, we are discussing SIMD in deep learning. Can anyone tell me what SIMD stands for?

Is it Single Instruction, Multiple Data?
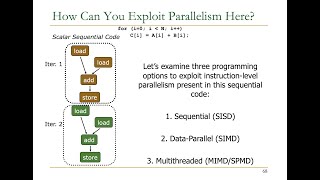
Exactly! SIMD allows a single instruction to simultaneously operate on multiple data points. This is very useful in deep learning, especially for tasks like matrix multiplication. Could someone explain why matrix multiplication is significant in neural networks?

It’s used in layer computations where inputs are transformed.
Right! And SIMD accelerates these operations, making the neural network training faster. This also highlights parallelism in deep learning. Can anyone define what parallelism means in this context?

It means processing many data points at the same time.
Correct! To some it up, SIMD helps achieve higher throughput by leveraging parallelism in deep learning tasks.
Comparison of SIMD and SIMT
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

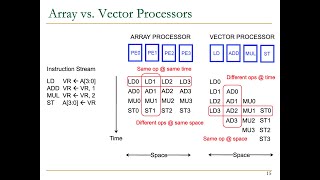
Now that we understand SIMD, let’s compare it with SIMT, which stands for Single Instruction, Multiple Threads. How do you think they differ?

I think SIMD processes multiple data items identically, while SIMT allows different threads to operate individually?
Well put! SIMD executes the same instruction on multiple data. In contrast, SIMT offers flexibility, enabling each thread to execute different operations based on the data it handles. Why is this flexibility important?
It allows for more complex operations that might not be feasible with SIMD alone.
Precisely! Understanding these differences helps us better appreciate how GPUs optimize for varying workloads. Let’s summarize: SIMD focuses on parallel data processing, and SIMT gives us flexibility at the cost of some parallelism.
Real-world Applications of SIMD in Deep Learning
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let’s dive into real applications of SIMD in deep learning. Can anyone think of a real-world task where SIMD boosts performance?
Convolution operations in convolutional neural networks!
Yes! Convolution operations involve processing large matrices, and SIMD enables these operations to happen quickly across all input pixels. What benefit do you think this brings to designing models?
It speeds up the training process, allowing us to iterate faster.
Exactly! Faster iterations mean quicker results and more effective model optimization. Let’s wrap up: SIMD accelerates computational operations in deep learning, especially for tasks critical in training complex models.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
SIMD allows deep learning frameworks to efficiently manage operations on large datasets, such as matrix multiplications. The section emphasizes how GPUs utilize SIMD to achieve performance improvements in training and inference processes, illustrating its fundamental importance in modern deep learning applications.
Detailed
In deep learning, SIMD (Single Instruction, Multiple Data) plays a critical role by allowing multiple operations to be executed in parallel, particularly for tasks such as matrix multiplication and convolutional operations, which are pervasive in neural network training and inference. This section details how GPUs harness SIMD capabilities to process large matrices substantially faster than traditional methods. With GPU cores functioning as SIMD units, they exploit data-level parallelism to handle many data points simultaneously, significantly enhancing computational efficiency. Furthermore, it contrasts SIMD with SIMT (Single Instruction, Multiple Threads), where each thread can perform distinct operations, thus providing flexibility while retaining SIMD's parallel data processing advantages.
Youtube Videos

Audio Book
Dive deep into the subject with an immersive audiobook experience.
Importance of SIMD in GPUs
Chapter 1 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
GPUs are inherently SIMD processors, with their architecture designed to execute the same instruction across many data points simultaneously. This makes GPUs highly efficient for tasks that can be parallelized.
Detailed Explanation
GPUs, or Graphics Processing Units, are built to handle many operations at once. This is possible because they leverage a technique called SIMD (Single Instruction, Multiple Data). With SIMD, a single instruction can process many data points at the same time, which is perfect for tasks that can benefit from parallelization. By using this capability, GPUs can perform computations much faster than traditional processors that execute instructions one at a time.
Examples & Analogies
Think of a factory assembly line. If one person is tasked with assembling a single item at a time, production is slow. However, if multiple workers can assemble different parts of many items at once, production speeds up significantly. Similarly, by using SIMD, GPUs can process multiple pieces of data simultaneously, leading to much faster computation.
SIMD in GPU Cores
Chapter 2 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
GPU cores are SIMD units that can execute the same instruction on multiple data elements in parallel. For example, in a graphics rendering pipeline, the same set of operations (such as shading) needs to be applied to many pixels or vertices.
Detailed Explanation
Each core in a GPU is considered a SIMD unit, meaning that it can execute the same instruction for different data elements at the same time. For instance, during the process of rendering graphics, every pixel may require the same shading computation. Instead of shading each pixel sequentially, the GPU can apply the shading to many pixels simultaneously, massively improving performance.
Examples & Analogies
Imagine a painter who needs to paint a large wall. If they paint one section at a time using a brush, it takes a lot of time to finish. However, if the painter uses a large roller, they can apply paint over a wide area quickly. This is akin to how GPU cores work—by executing the same instruction across many data elements, they complete tasks quickly.
Understanding SIMT
Chapter 3 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
SIMD vs. SIMT (Single Instruction, Multiple Threads): SIMD refers to processing multiple data elements with a single instruction within a single thread. SIMT is a model used by modern GPUs where each thread executes the same instruction on its own data element. Although similar to SIMD, SIMT provides greater flexibility by allowing different threads to perform different tasks.
Detailed Explanation
While SIMD processes multiple data elements in a single thread, the SIMT approach used by GPUs allows individual threads to carry out the same instruction but on different data elements. This means while there may be a single instruction sending operations out, different threads can handle various tasks if required. This flexibility allows for complex processing without sacrificing parallel performance.
Examples & Analogies
Think of a cooking class where a chef teaches a recipe. In SIMD, all students follow the same instructions and cook the same dish together at once. In SIMT, each student can choose to follow the same basic recipe but can add their unique twist or ingredient. This allows each student to participate with creativity, similar to how SIMT allows threads flexibility in execution.
Applications of SIMD in Deep Learning
Chapter 4 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
In deep learning, GPUs accelerate operations like matrix multiplication (used in neural networks) by exploiting SIMD. Large matrices are processed in parallel using SIMD operations, drastically speeding up training and inference.
Detailed Explanation
Deep learning relies heavily on operations like matrix multiplications, which are foundational to how neural networks learn. By utilizing SIMD, GPUs can perform these matrix operations on large datasets simultaneously, rather than one at a time. This parallel processing significantly reduces the time required for both training the models and making predictions (inference), making it feasible to work with larger datasets and more complex models.
Examples & Analogies
Picture a classroom with a teacher explaining complex mathematics on a large board. If each student copies the solutions one by one, it takes ages. Now, if all students receive the same set of equations and start solving on their own at the same time, they will finish much quicker. Similarly, in deep learning, GPUs use SIMD to handle matrix calculations in parallel, speeding up the entire process.
Key Concepts
-
SIMD: A method that allows simultaneous operations on multiple data points, enhancing performance in computational tasks.
-
GPU Efficiency: GPUs utilize SIMD to process tasks like matrix multiplication efficiently in deep learning applications.
-
Parallelism: The practice of executing multiple operations at the same time, crucial in optimizing deep learning performance.
Examples & Applications
In a convolutional neural network, SIMD enables processing all pixels of an image simultaneously, improving the speed of feature extraction.
During training, a GPU leverages SIMD to perform several matrix multiplications concurrently, significantly reducing the training time for neural networks.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
SIMD brings data speed, while training our models we do feed.
Stories
Imagine a chef preparing a feast. SIMD is like having many cooks, each chopping different vegetables simultaneously to speed up the meal preparation.
Memory Tools
Remember 'SIMPle Data Processing' to recall SIMD immediately!
Acronyms
Use 'SPEED' to remember
'Single Instruction Processing for Efficient Data'.
Flash Cards
Glossary
- SIMD
Single Instruction, Multiple Data - a parallel computing method allowing one instruction to act on multiple data points simultaneously.
- SIMT
Single Instruction, Multiple Threads - a model where each thread executes the same instruction on its data, allowing unique operations for each.
- Matrix Multiplication
A mathematical operation that produces a matrix from two matrices, fundamental in neural network operations.
- Parallelism
The capability to process multiple data elements simultaneously, enhancing throughput in computations.
- GPU
Graphics Processing Unit - specialized hardware designed to accelerate the processing of large amounts of data.
Reference links
Supplementary resources to enhance your learning experience.