
Compiler Vectorization
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to Compiler Vectorization
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Welcome everyone! Today, we're diving into compiler vectorization. Can anyone tell me what vectorization means?

Is it about processing multiple data points at once?
Exactly! Vectorization allows us to take scalar operations—like adding two numbers—and convert them into vector operations to handle multiple numbers simultaneously. This makes programs much faster.

How do modern compilers help with this?
Great question! Compilers like GCC and Clang automatically analyze loops and optimize them for vectorized operations. This is known as automatic vectorization. Can anyone think of a scenario where this would be beneficial?

Maybe in video processing where lots of pixels are handled?
Exactly! In graphics, processing each pixel can be vectorized to enhance performance. To remember these terms, let's create a mnemonic: 'Vectors Accelerate Computing Tasks' or VACT!

That's clever! What about manual vectorization?
Manual vectorization allows developers to explicitly write code using SIMD instructions for even better performance in critical areas. Any thoughts on when this might be necessary?
In high-performance computing where every second counts?
Exactly right! To recap today, vectorization can occur automatically through compilers or manually to optimize performance, especially in demanding applications.
Challenges of Vectorization
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Now, let's talk about some challenges we face with vectorization. What do you think could hinder automatic vectorization?
Maybe if one loop depends on the output of another loop?
That’s spot on! Loop dependencies can make it very difficult to vectorize. When each iteration relies on the previous one, it disrupts the parallel nature of vectorization. What else can be a problem?
Data alignment? Like when data isn’t in the right format for SIMD?
Absolutely! Memory alignment is crucial because SIMD instructions perform best when data matches the vector register size. Misalignment can lead to inefficiencies. To remember this, think of it as 'Aligned Data, Accelerated Execution' or ADAE!
So we need to make sure our data is well organized before vectorization?
Exactly! In summary, challenges like loop dependencies and memory alignment impact how effectively we can vectorize our code.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
In this section, compiler vectorization is explored as a method to transform scalar operations into vector operations through modern compilers like GCC and Clang. It highlights both automatic and manual vectorization techniques, the challenges faced by developers, and optimizations necessary for effective vectorization.
Detailed
Compiler Vectorization
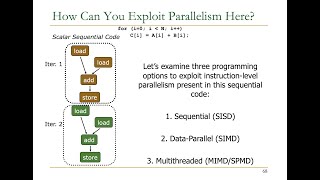
Compiler vectorization is a crucial optimization technique that transforms scalar operations—those applied to single data points—into vector operations, which can handle multiple data points simultaneously. This process is integral in modern computing, especially for performance-critical applications in fields like scientific computing and graphics.
Key Concepts
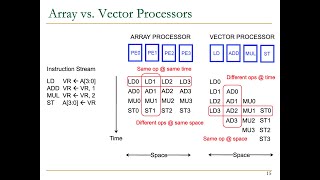
- Automatic Vectorization: Modern compilers like GCC and Clang can automatically analyze loops and identify opportunities to convert scalar operations into SIMD instructions. This automation simplifies the programmer's task, allowing them to focus on overall algorithm design.
- Manual Vectorization: Developers can also optimize vectorization manually, by using libraries or intrinsic functions that exploit the capabilities of SIMD hardware directly. This is particularly valuable in high-performance contexts, where the cost of each operation significantly affects performance.
- Challenges: Vectorization faces hurdles such as loop dependencies, where an iteration’s output is needed for the next, hindering automatic vectorization. Additionally, memory alignment issues can affect the performance of SIMD instructions, as they work best with data that aligns with the register size (e.g., 128-bit, 256-bit).
Overall, understanding and applying compiler vectorization techniques is essential for enhancing the efficiency and speed of applications in high-performance computing frameworks.
Youtube Videos

Audio Book
Dive deep into the subject with an immersive audiobook experience.
Overview of Compiler Vectorization
Chapter 1 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Vectorization is the process of converting scalar operations (operations on single data points) into vector operations (operations on multiple data points). This process can be automated through compilers, or manually optimized by the developer.
Detailed Explanation
Compiler vectorization transforms code that operates on one piece of data at a time into code that can handle multiple pieces simultaneously. This transformation enables programs to execute faster because they can take advantage of modern CPU capabilities designed for parallel operations. Compilers, such as GCC and Clang, can perform this transformation automatically, allowing programmers to write more straightforward code without dealing with the complexities of SIMD (Single Instruction, Multiple Data) manually.
Examples & Analogies
Imagine cooking a meal where you need to chop vegetables. If you're doing it one by one, it takes a long time. But if your friend comes over, and you both work together, you can chop multiple vegetables at once. Compiler vectorization is like having your friend help you—allowing your computer to 'chop' multiple pieces of data in parallel, making the cooking (or computation) process much quicker.
Automated Vectorization
Chapter 2 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Compiler Vectorization: Modern compilers, such as GCC and Clang, can automatically vectorize loops where possible. This involves converting scalar operations to SIMD instructions, enabling parallel execution.
Detailed Explanation
When a programmer writes loops that perform the same operation on a collection of data, modern compilers analyze these loops and automatically transform them to use SIMD instructions where applicable. This means that instead of each iteration of the loop processing a single data point sequentially, the compiler generates code that processes several data points at once. This automatic improvement significantly boosts performance without requiring the programmer to write complex SIMD code manually.
Examples & Analogies
Think of a factory assembly line. Normally, one worker might be assembling one toy at a time. However, with an automated system, a machine can assemble multiple toys simultaneously. Just like the machine improves output by working on many toys at once, compiler vectorization enhances code efficiency by executing multiple operations at the same time.
Manual Vectorization
Chapter 3 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Manual Vectorization: Developers can write code that explicitly uses SIMD instructions, leveraging libraries and intrinsic functions to access SIMD hardware features directly. This is often done for performance-critical code, such as in high-performance computing (HPC) and graphics.
Detailed Explanation
While automatic vectorization is beneficial, developers also have the option to manually optimize their code. This involves using specific libraries or intrinsic functions that directly correspond to SIMD instructions. Manual vectorization is particularly useful in situations where maximum performance is necessary, such as in graphics processing or scientific simulations, where performance gains from parallelization can lead to significant improvements in speed and efficiency.
Examples & Analogies
Consider a professional chef who knows all the tricks to maximize efficiency, like using special tools and techniques for chopping and mixing. Similarly, a developer skilled in manual vectorization can optimize their code using specialized SIMD techniques, making their programs run as efficiently as possible—just as a chef produces the finest dishes in the shortest time.
Challenges in Vectorization
Chapter 4 of 4
🔒 Unlock Audio Chapter
Sign up and enroll to access the full audio experience
Chapter Content
Challenges in Vectorization:
○ Loop Dependencies: Some loops cannot be easily vectorized due to data dependencies, where the result of one iteration is needed for the next iteration.
○ Memory Alignment: SIMD instructions work most efficiently when data is aligned in memory, meaning that the start of the data in memory is aligned with the boundary of the vector register size (e.g., 128-bit, 256-bit).
Detailed Explanation
Vectorization can encounter difficulties due to two main factors: loop dependencies and memory alignment. Loop dependencies occur when one iteration of a loop relies on the result from a previous iteration, making it impossible to execute them in parallel. Memory alignment refers to the positioning of data in memory, which must align with the size of the vector registers for SIMD instructions to work efficiently. If the data is not aligned correctly, the performance gains may diminish, which means the programmer has to ensure that their data structures meet these requirements.
Examples & Analogies
Imagine passing a baton in a relay race. If one runner depends on the previous runner to finish before they can start, it slows down the whole team—that's like a loop dependency. On the other hand, consider a train on tracks that aren't laid out properly; if the tracks aren’t aligned, the train won't run smoothly. In coding, if the memory isn’t aligned correctly, the SIMD instructions won’t run as efficiently as they should.
Key Concepts
-
Automatic Vectorization: Modern compilers like GCC and Clang can automatically analyze loops and identify opportunities to convert scalar operations into SIMD instructions. This automation simplifies the programmer's task, allowing them to focus on overall algorithm design.
-
Manual Vectorization: Developers can also optimize vectorization manually, by using libraries or intrinsic functions that exploit the capabilities of SIMD hardware directly. This is particularly valuable in high-performance contexts, where the cost of each operation significantly affects performance.
-
Challenges: Vectorization faces hurdles such as loop dependencies, where an iteration’s output is needed for the next, hindering automatic vectorization. Additionally, memory alignment issues can affect the performance of SIMD instructions, as they work best with data that aligns with the register size (e.g., 128-bit, 256-bit).
-
Overall, understanding and applying compiler vectorization techniques is essential for enhancing the efficiency and speed of applications in high-performance computing frameworks.
Examples & Applications
Using a loop to sum elements of an array can be vectorized to compute multiple sums in parallel, significantly improving performance.
When processing a large image, vectorized operations can apply the same filter to every pixel simultaneously, speeding up rendering.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
Vectorization's a clever invitation, to speed up our computation!
Stories
Imagine a factory where each worker represents a CPU core. When one worker can only handle one item at a time (scalar), production is slow. Now imagine multiple workers (vectorization) working on many items simultaneously—production skyrockets!
Memory Tools
For compiler vectorization, remember 'VAULT': Vectorization Automatically Utilizes Loop Techniques.
Acronyms
SPEED – Scalar to Parallel Efficient Execution with Data.
Flash Cards
Glossary
- Compiler Vectorization
The process of converting scalar operations into vector operations, often automated by compilers for performance optimization.
- Automatic Vectorization
The capability of compilers to detect opportunities for vectorizing code without manual intervention.
- Manual Vectorization
The process where developers explicitly write code using SIMD instructions to optimize performance.
- Loop Dependencies
Situations where the output of one iteration in a loop affects the next iteration, hindering parallelization.
- Memory Alignment
The arrangement of data in memory to conform with the boundaries of vector register sizes for optimal SIMD instruction performance.
Reference links
Supplementary resources to enhance your learning experience.