
SIMD in GPU Cores
Enroll to start learning
You’ve not yet enrolled in this course. Please enroll for free to listen to audio lessons, classroom podcasts and take practice test.
Interactive Audio Lesson
Listen to a student-teacher conversation explaining the topic in a relatable way.
Introduction to SIMD in GPU Cores
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Today, we're discussing how GPUs utilize SIMD, or Single Instruction, Multiple Data, to perform many calculations at once. This makes them extremely efficient for tasks like graphics rendering.

So, is SIMD only available in GPUs?
Great question! While GPUs are optimized for SIMD, modern CPUs also implement SIMD technologies to improve performance.

Can you give an example of SIMD at work?
Certainly! When rendering an image, the same operation to shade pixels can be applied simultaneously using SIMD.
Remember, SIMD helps in maximizing throughput, which is essential in processing large datasets quickly.
SIMD vs. SIMT
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson

Now let's dive into the difference between SIMD and SIMT. SIMD processes multiple data points within a single thread, while SIMT allows each thread to operate independently.

Does that mean SIMT is more flexible than SIMD?
Exactly! SIMT provides greater flexibility, as different threads can execute different instructions on their data.

Why would a GPU prefer to use SIMD though?
GPUs favor SIMD for applications that require the same computation on a bulk of data, which results in faster processing times, especially in graphics and machine learning tasks.
So, if we summarize: SIMD is great for uniform tasks, while SIMT gives us flexibility.
Applications of SIMD in Deep Learning
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Let's look at how SIMD plays a crucial role in deep learning. When training neural networks, operations like matrix multiplication are performed.
Can you explain how SIMD is applied there?
Of course! SIMD can handle operations across large matrices simultaneously, speeding up both training and inference phases dramatically.
What if the data isn't aligned properly?
Good point! Proper memory alignment is crucial for SIMD to work efficiently, as misalignment can slow down execution.
Overall, SIMD enhances performance by maximizing the use of GPU resources in deep learning applications.
Overview of GPU Architecture
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
To wrap up, let's summarize the architecture of GPUs that supports SIMD operations. They consist of thousands of small cores designed for parallel processing.
So, the more cores there are, the better the performance?
Generally speaking, yes! More cores mean more capability to process multiple instructions simultaneously, which is key for high-performance tasks.
Are there any limitations to this approach?
Limitations do exist, particularly around issues like memory bandwidth and the need for parallelizable tasks. However, for large datasets, SIMD is incredibly effective.
The Future of SIMD in GPUs
🔒 Unlock Audio Lesson
Sign up and enroll to listen to this audio lesson
Looking ahead, SIMD in GPUs will evolve to tackle more complex workloads. What do you think might drive this change?
Perhaps advancements in AI and machine learning?
Exactly! The growing demands of these fields will push for improved SIMD capabilities.
What about other technologies like quantum computing?
That's an interesting angle. Future GPUs might incorporate elements of quantum processing to enhance their capabilities further.
To summarize, the future of SIMD in GPUs looks bright, with ongoing research and development likely to expand its applications.
Introduction & Overview
Read summaries of the section's main ideas at different levels of detail.
Quick Overview
Standard
This section discusses the role of SIMD in GPU cores, highlighting how their architecture naturally supports executing the same instruction on multiple data points. It also contrasts SIMD with SIMT (Single Instruction, Multiple Threads) to illustrate the flexibility and efficiency of modern GPUs in processing graphics and deep learning tasks.
Detailed
SIMD in GPU Cores
GPUs are fundamentally designed as SIMD processors, meaning they excel in executing the same instruction across many data elements concurrently. This feature is critical in applications such as graphics rendering and deep learning, where efficiency and speed are paramount.
Key Points
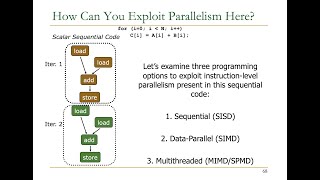
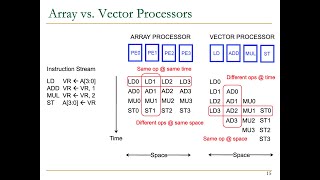
- SIMD Execution in GPU Cores: GPU cores act as SIMD units performing identical operations on multiple data elements. For instance, during graphic rendering, a shader applies the same operations to many pixels or vertices at once.
- Difference between SIMD and SIMT: While SIMD focuses on multiple data elements under a single instruction within one thread, SIMT enables each thread to perform operations independently on their data. This provides more flexibility, allowing varied tasks across different threads, which is a common requirement in GPU programming.
- Applications in Deep Learning: GPUs exploit SIMD to accelerate deep learning processes like matrix multiplication. By processing large matrices simultaneously, training and inference tasks can be accomplished much faster than in traditional CPUs.
The significance of SIMD in GPU cores lies in its ability to maximize throughput and efficiency when handling large datasets, making GPUs a go-to solution for high-performance computing.
Youtube Videos

Key Concepts
-
SIMD: A method for processing multiple data elements simultaneously using a single instruction.
-
SIMT: Allows different threads to execute the same instruction on their unique data, providing more flexibility.
-
Throughput: Refers to the volume of data processed in parallel by the GPU.
-
Matrix Multiplication: A fundamental operation in machine learning tasks, significantly sped up by SIMD.
Examples & Applications
When rendering an image, SIMD allows the same shading operation to be applied to multiple pixels at the same time.
In deep learning, SIMD accelerates the matrix multiplications needed for training neural networks, processing numerous calculations simultaneously.
Memory Aids
Interactive tools to help you remember key concepts
Rhymes
In GPU cores where data flows, SIMD makes processing grow; executing commands at a fast pace, it’s faster than a running race.
Stories
Imagine a painter who has a massive canvas filled with pixels. With SIMD, they can apply the same color to hundreds of pixels at once, making the entire painting process much quicker.
Memory Tools
To remember SIMD and SIMT: Single Instruction for Multiple Data vs. Single Instruction for Multiple Threads.
Acronyms
Think of SIMD as **S**peedy **I**nstructions for **M**assive **D**atasets.
Flash Cards
Glossary
- SIMD
Single Instruction, Multiple Data; a parallel computing method that executes a single instruction on multiple data points simultaneously.
- SIMT
Single Instruction, Multiple Threads; a programming model that allows individual threads to execute the same instruction on their own data.
- GPU
Graphics Processing Unit; specialized hardware designed for parallel processing, commonly used for tasks like rendering and deep learning.
- Matrix Multiplication
An operation where two matrices are multiplied to produce a new matrix, frequently used in machine learning and graphics computations.
- Throughput
The amount of processing that occurs in a given period; in the context of GPUs, it refers to how much data can be processed simultaneously.
Reference links
Supplementary resources to enhance your learning experience.